2018-1-4
0x00 前言
之前我们部门内部进行过几次关于应急响应的分享,主要讲了几个具体的应急分析案例以及一些具体的技术,并没有从一个比较大的角度说明应急是什么。所以,我想根据自己这一年多的应急响应经验来谈谈自己对应急的一些理解。
0x01 应急的种类
从目前遇到的情况来看,应急大致可以分成两大类,一类是事件型应急,一类是异常型应急。所谓事件型应急,即针对当下流行安全事件、漏洞进行的应急动作,比如s2漏洞爆发、永恒之蓝漏洞被大范围利用的时候,企业为了确认自己的网络资产是否可能受到影响或者是否已经受到影响而产生的应急;而异常型应急则是企业发现自己的业务出现了非预期的情况(业务的不正常表现或已经确认被黑),想要搞清楚这种异常出现的原因而产生的应急。
0x02 应急的目的
做任何事情都有目的,应急也是如此。不同情况的应急,目的不尽相同,其实从应急事件产生的原因描述中就能知道应急的目的。对于事件型应急来说,应急分析的目的就是确认安全事件对企业资产的影响;对于异常型应急来说,应急分析的目的则是找到异常产生的原因并解决,保证企业业务在今后一段时间内不再因此而出现问题。
之所以提一下应急的目的,是因为如果目的不明确的话,面对比较复杂的应急场景时,思路很容易不清晰。特别是很多异常型的应急,如果不能明确“找到异常的原因”这一目的,思维往往会很混乱。至于抓捕攻击者、追回企业损失之类的行为,需要根据应急分析的结果来决定做不做以及如何去做,不属于应急分析的直接目的。
0x03 应急的方法 本节描述应急分析时一些常用的方法,不涉及具体技术。
(1)据实分析
所谓据实分析,即根据应急时发现的具体信息,来判断发生过什么。这种分析完全依据已存在的事实,比如如果发现服务器上存在一个root用户的计划任务后门,就可以知道服务器的root权限被攻击者获取了;如果发现服务器Web目录下存在一句话木马,就可以知道攻击者获取到了Web服务权限;如果发现Web访问日志中出现了SQL注入的利用痕迹,就要自己去确认SQL注入是否利用成功。
据实分析是应急分析过程中最常用的方法,一般来说,一次应急过程中,据实分析法占比越高,那么这次应急分析的结论就越可靠。
(2)合理猜测
能通过据实分析来达到应急分析目的的情况少之又少,当不能完全通过分析已存在事实来得到完整的应急结果时,合理猜测就成为一种重要的方法。
比如,你在网站目录下发现了Webshell,同时确认网站存在s2命令执行漏洞,但是Web相关日志全部被清空,没有办法确认s2漏洞是否被利用过。这时候通过分析,发现这台主机上仅仅存在一个Web服务,没有其他已知问题,这时候就可以猜测Webshell就是通过s2漏洞上传,之后可基于这个猜测去做进一步的分析,看是否能找到其他事实来印证这个猜测。
这里需要特别注意的是,合理猜测方法是在无法进行据实分析的情况下才考虑采用的方法,而且一定是“合理”猜测,绝不是毫无根据的臆测。如果一次应急过程中合理猜测的占比过高,那么这次应急的结论就需要被谨慎对待。
(3)积极沟通
积极与企业相关人员进行沟通是做应急分析时非常重要的一个方法。基本的道理就是企业相关人员对自身网络资产、对自身业务、对出现的异常现象,要比我们应急分析人员熟悉的多,积极和他们沟通可以节省我们很多时间,并且更容易得出正确的结论。比如你在一台服务器上发现了一个奇怪的进程,此时就可以考虑直接询问企业相关人员这个进程他们是否了解,而不是自己对该进程进行分析;或者你发现服务器上有计划任务定时与某个IP通信,这时候也需要向企业相关人员进行了解,确认这样的行为是否是企业业务的正常需要,得到反馈之后再去进一步分析。
在做应急分析时,上述三种方法都会用到。一般的情况是,在据实分析的基础上,与企业相关人员进行沟通,辅以合理猜测,最后得出结论,这就是做应急分析的一般方法。当然,应急时面对的情况可能各种各样,方法和手段也要根据具体的情况来调整,只要时刻想着做应急响应的目的,就一定能想出解决问题的办法。
以针对汇量科技大量gitlab用户信息泄露事件的应急为例,客户收到匿名黑客发来的邮件,部分内容如图:
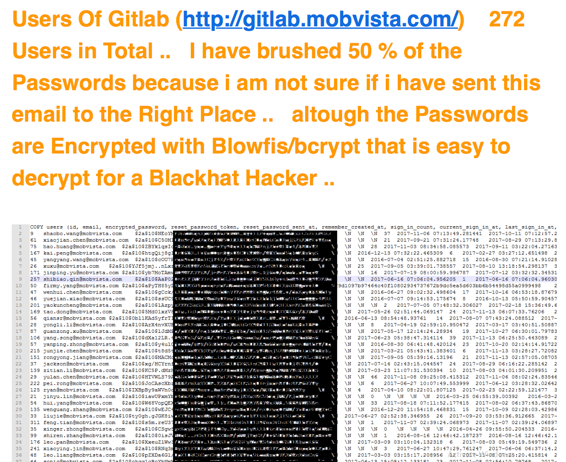
gitlab子域名之前经过我们的渗透测试,并未发现比较严重的问题。当时我首先对gitlab服务器进行常规分析,未发现明显的入侵痕迹,之后和客户沟通,了解到获取这些信息有两个途径,一个是服务器上的数据库备份,另一个是亚马逊云存储上的数据库备份。根据客户的反馈信息,结合之前的排查,我便猜测可能是客户亚马逊云某高权限Access Key泄露导致了该事件,后经客户确认确实如此。
0x04 应急的核心能力
这一节想说的是,对于应急来说,安全工程师的价值到底体现在哪里?说起对系统和网络的一些认知和操作,我们可能都比不上企业专业的运维人员,更不用说对企业业务的了解了,有些业务我们可能一点儿都不懂。在这种情况下,安全工程师凭什么去做应急?简单来说就是四个字——安全经验。
那么安全经验具体体现在哪些地方呢?
对于事件型应急来说,对相应事件、漏洞是否足够熟悉,决定了你能否做好这次应急。以s2漏洞爆发为例,比如首先要去看服务器是不是已经被黑,作为一个企业的运维人员,可能会从进程、文件、网络连接信息等方面入手去检查,那么作为一个安全工程师,仅做这些常规的检查不能体现出我们的价值。当这个漏洞爆发的时候,安全工程师就应该立刻关注它,搞清楚漏洞的原理、利用方式、危害、修复方法以及对于应急分析来说特别重要的一点——利用痕迹。在条件允许的情况下,最好是能通过亲自动手分析来搞明白这些问题,条件不允许时(比如没时间或者能力不对位)则要积极关注别人的研究成果,收为己用。回到s2漏洞,经过以上家庭作业,安全工程师发现,使用网上公开的一些漏洞利用工具进行漏洞利用时,在Tomcat的common日志中会留下痕迹,如下图所示:
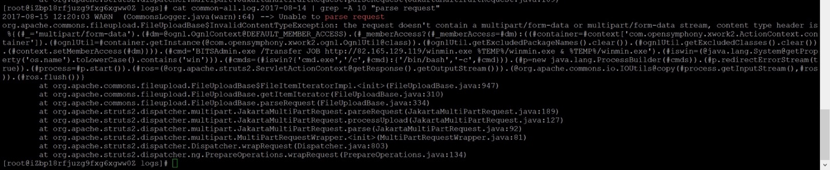
针对Wannacry事件的应急也是如此,通过阅读网上大量公开的病毒样本分析报告,就能知道该病毒的传播原理(永恒之蓝)、现象(请求“开关”域名、勒索、蓝屏等)以及解决方案。了解这些之后再去做应急,就会有底气。
而对于异常型应急来说,安全工程师在应急过程中有一个重要的任务,就是要确认异常是否由安全事件所引起。在这种情况下,作为安全工程师,要能够根据服务器的一些基本信息(如版本信息、端口信息、服务配置信息等)来推测可能存在的安全问题,然后根据推测去确认问题是否存在,最后确认异常是否由安全问题所引起。以之前针对比特大陆200个比特币丢失事件的应急为例,开始时我们通过一些基本的分析,发现相关业务代码中的比特币钱包地址被篡改,但是攻击者如何获取到服务器权限一直搞不清楚。这时,作为众人的偶像,葛新亮大佬根据系统日志中服务器似乎重启过的痕迹,结合服务器在阿里云上的基本信息,凭借安全经验,推测攻击者通过阿里云的镜像操作来控制服务器,依靠这个关键的合理猜测,逐步分析下去,居然找到了偷取比特币的攻击者!正因为安全工程师了解这种攻击方式,才能解决这次应急遇到的问题,这就是安全经验的体现。
0x05 一次非常规手段的应急
为什么会出现非常规的应急手段呢?因为我发现通过常规的方法,不能解决客户的问题(应急可能是最直接体现安服价值的活动)。
客户在自己的业务服务器上发现了Webshell,这时候应急分析的目的就很明确了,就是要搞清楚Webshell是怎么被放到服务器上的,然后采取一些办法来加固。这时我遇到的问题是,我通过对他们业务代码进行审查,确实发现了能够上传Webshell的漏洞,但由于客户之前没有开Web访问日志,而我无论如何也不能保证代码中没有其他漏洞,所以不能确认攻击者是否利用该漏洞进行攻击。
通过与客户沟通,在客户确认能hold住的情况下,我建议客户开启Web访问日志,删除之前的后门,然后去激怒攻击者(客户似乎知道攻击者是哪些人),诱使攻击者再来进行攻击。通过这种方式,我从Web访问日志中确认了攻击者确实是通过该漏洞上传的Webshell。
0x06 存在决定意识,量变引起质变
前面没有提到应急时具体的技术点,因为不是本文重点。但存在决定意识,如果一个人对Linux、Windows系统的基本信息、基本操作都不了解,那么肯定做不好应急。
此外,一些技巧性的操作,也会造成量变引起质变的现象。比如,如何从大量的Web访问日志中快速过滤你想关注的信息?如果对awk、grep等工具运用不熟练,很可能因错过关键信息而无法很好的完成应急分析工作。
0x07 总结
我从一些比较大的方面谈了一下自己对应急的一些理解,描述了我认为的应急的分类、目的、方法等内容,特别提到了我认为在应急分析活动中,作为安全工程师应该具备的核心能力。希望能给不熟悉应急响应的小伙伴一些帮助,让大家在面对应急工作时能够更加从容,可以尽早独立完成应急响应工作。
最后,通读了整篇文章,发现并没有体现出我的文学天才,很烦。