推理模型
动机
大语言模型的一个重要应用方向是构建通用系统,使其能够处理各类自然语言处理任务。在本次作业中,我们将聚焦于语言模型一个新兴的应用场景:数学推理。该场景将作为实验平台,用于搭建评估流程、执行监督微调,并尝试通过强化学习(RL)训练语言模型掌握推理能力。
本作业使用的基础模型:Qwen 2.5 Math 1.5B Base,使用 GSM8K 数据集完成对模型的评估。
思维链推理与推理强化学习
LLM的思维链推理:早期的思维链方法通过微调语言模型,借助 “草稿板” 将问题拆解为中间步骤,以此解决算术等简单数学任务 [Nye 等人,2021]。其他研究通过提示强模型在作答前 “逐步思考”,发现该方式能显著提升小学数学题等数学推理任务的性能 [Wei 等人,2023]。
基于专家迭代的推理学习:自学习推理器(STaR)[Zelikman 等人,2022] 将推理建模为自引导循环:预训练模型先采样多样化的思维链(CoT),仅保留能推导出正确答案的推理过程,再基于这些 “专家级” 推理轨迹进行微调。反复迭代该循环可提升语言模型的推理能力与解题正确率。STaR 验证了这种专家迭代方法 [Anthony 等人,2017]—— 仅通过基于字符串匹配的自动校验机制验证生成答案,无需人工编写推理轨迹,就能自主习得推理能力。
基于可验证奖励的推理强化学习(o1、R1):近期研究探索使用更强大的强化学习算法,结合可验证奖励提升推理性能。OpenAI 的 o1(及后续 o3/o4)[OpenAI 团队,2024]、DeepSeek的 R1 [深度求索团队,2025]、月之暗面的 kimi k1.5 [团队等人,2025] 均采用策略梯度法 [Sutton 等人,1999],在可通过字符串匹配或单元测试验证正确性的数学与代码任务上训练,在竞赛数学与代码任务中实现了显著的性能提升。后续如 Open-R1 [Face 团队,2025]、SimpleRL-Zoo [Zeng 等人,2025]、TinyZero [Pan 等人,2025] 等研究进一步证实:即便在 15 亿参数级别的小模型上,纯强化学习搭配可验证奖励也能有效提升推理性能。
Zero-Shot数据集评测
使用r1_zero的prompt:

(在Qwen 2.5 Math 1.5B上,这个prompt并非最优。有研究发现仅向模型输入问题(不附加任何其他内容)就能达到很高的准确率。)
使用 vLLM 进行离线大语言模型推理
本次作业使用 vLLM 进行离线批处理推理。vLLM 是一款面向大语言模型的高吞吐、内存高效推理引擎,集成了多种实用的性能优化技术(例如优化后的 CUDA 内核、用于高效注意力 KV 缓存的 PagedAttention [Kwon et al., 2023] 等)。
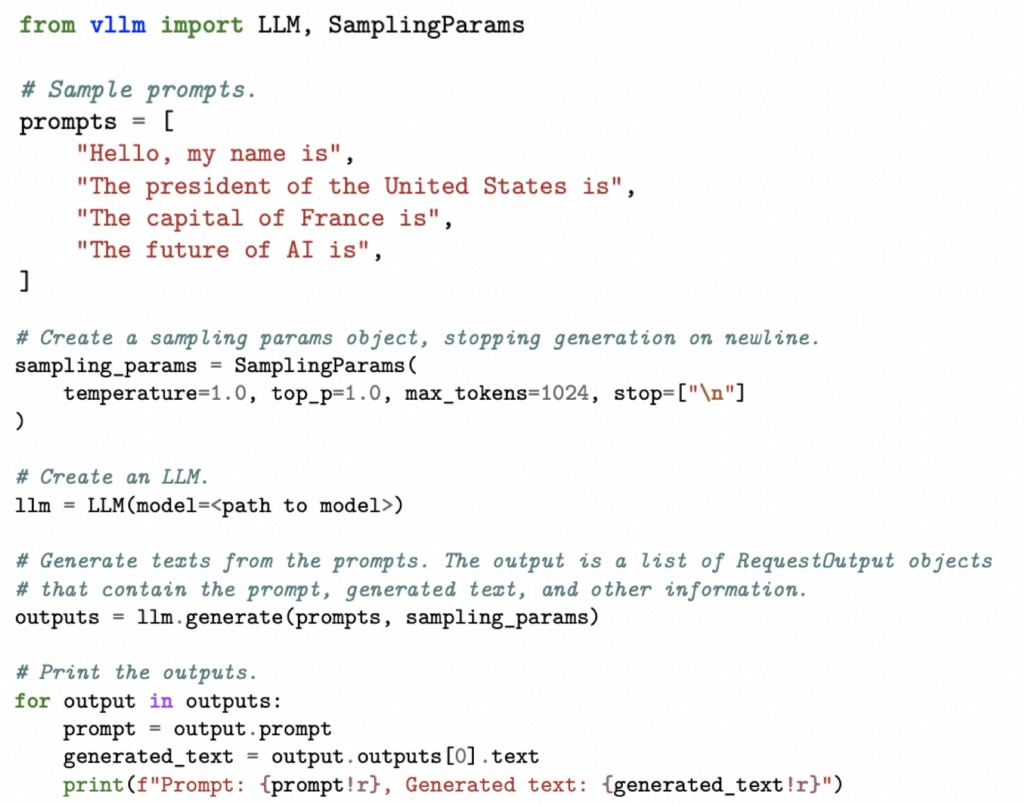
Zero-shot GSM8K Baseline
def evaluate_vllm(
vllm_model: LLM,
reward_fn,
prompts: List[str],
eval_sampling_params: SamplingParams,
ground_truth_list: List[str],
output_path
):
with open('/home/yc/my_project/data/assignment5-alignment/cs336_alignment/prompts/r1_zero.prompt', 'r') as f:
prompt_base = f.read()
handled_prompts = [prompt_base.format(question=one) for one in prompts]
outputs = vllm_model.generate(handled_prompts, eval_sampling_params)
result = {
"all_1": 0,
"format_1": 0,
"all_0": 0
}
f_log = open(output_path, 'w')
for response, ground_truth in zip(outputs, ground_truth_list):
output = response.outputs[0].text
f_log.write("output:{}\nground_truth:{}\n".format(output, ground_truth))
f_log.write("=================================\n")
reward = reward_fn(output, ground_truth)
if reward['reward'] == 1.0:
result['all_1'] += 1
elif reward['format_reward'] == 1.0:
result['format_1'] += 1
else:
result['all_0'] += 1
f_log.close()
with open(f"{output_path}.result.json", 'w', encoding='utf-8') as f:
json.dump(result, f, indent=2)
return result['all_1']
def qwen_baseline(model_path, eval_output_path, eval_llm=None):
valid_data_path = '../data/gsm8k/test.jsonl'
#model_path = '../models/Qwen2.5-Math-1.5B'
with open(valid_data_path, 'r') as f:
lines = f.readlines()
prompts = []
ground_truth_list = []
for line in lines:
try:
l_data = json.loads(line.strip())
prompts.append(l_data['question'])
ground_truth_list.append(l_data['answer'])
except:
continue
sampling_params = SamplingParams(
temperature=1.0, top_p=1.0, max_tokens=1024, stop=["</answer>"], include_stop_str_in_output=True
)
if eval_llm is not None:
llm = eval_llm
else:
llm = LLM(model=model_path)
result = evaluate_vllm(llm, gsm8k_reward_fn, prompts, sampling_params, ground_truth_list, eval_output_path)
print('qwen_baseline done')
return resultbaseline结果:
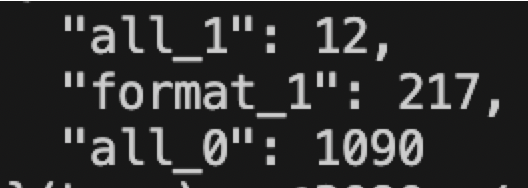
(all_1表示格式和答案都正确,format_1表示格式正确答案错误,all_0表示格式都不正确)
Supervised Fintuning for GSM8K
SFT:

在实际训练推理模型时,监督微调(SFT) 通常被用作后续强化学习(RL)微调阶段的热启动。主要原因有两点:第一,SFT 需要高质量的标注数据(即包含预先存在的推理轨迹),而 RL 仅需正确答案即可作为反馈。第二,即便在标注数据充足的场景下,RL 仍能通过学习比 SFT 数据更优的策略来实现性能提升。
Using HuggingFace Models

前向传播:

保存model和tokenizer:

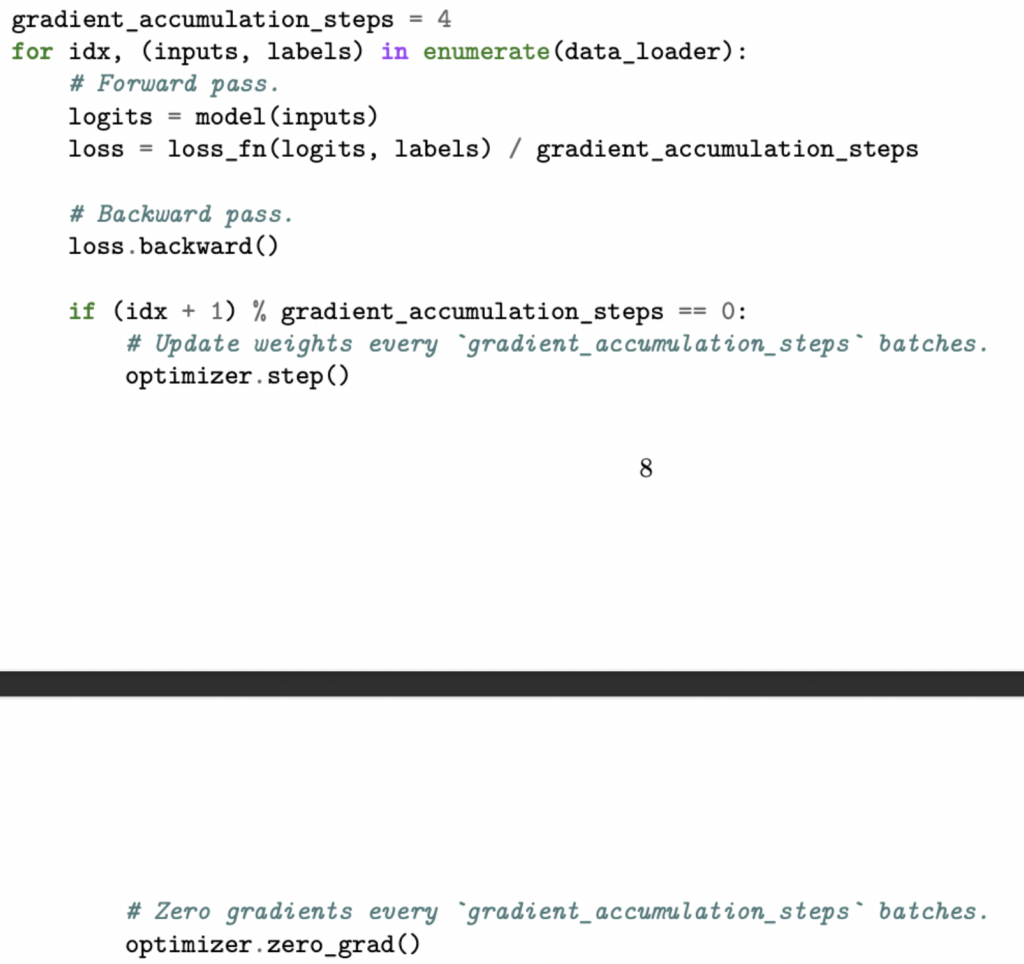
梯度累积:模拟更大的batch_size。其核心思想是:不必在每个批次后立即更新模型参数(即执行优化器步进),而是先在多个批次中累积梯度,再统一执行一次梯度更新。直观来说,如果我们拥有更大容量的显卡,一次性对包含 32 个样本的批次计算梯度,与将其拆分为 16 个批次(每个批次 2 个样本)并在最后取平均,得到的结果是一致的。
在PyTorch中使用梯度累积,每k步调用一次optimizer.step()和optimizer.zero_grad()即可:
SFT Helper Methods
Tokenizing prompts and outputs:对于每一组问题与目标输出对 (q,o),我们会分别对问题和输出进行分词,再将它们拼接起来。之后,我们就可以使用监督微调模型(或在后续章节中使用强化学习策略模型)计算输出部分的对数概率。
此外,我们还需要构建一个 response_mask(回复掩码):这是一个布尔型掩码,标记为 True 的位置对应回复部分的所有分词,标记为 False 的位置对应问题部分与填充部分的所有分词。我们会在训练循环中使用该掩码,以确保只在回复对应的分词上计算损失。
代码实现:
def run_tokenize_prompt_and_output(
prompt_strs: list[str],
output_strs: list[str],
tokenizer: PreTrainedTokenizerBase,
) -> dict[str, Tensor]:
"""Tokenize the prompt and output strings, and construct a mask that is 1
for the response tokens and 0 for other tokens (prompt or padding).
Args:
prompt_strs: list[str], the prompt strings.
output_strs: list[str], the output strings.
tokenizer: PreTrainedTokenizer, the tokenizer to use.
Returns:
dict[str, torch.Tensor]:
"input_ids": torch.Tensor of shape (batch_size, max(prompt_and_output_lens) - 1):
the tokenized prompt and output strings, with the final token sliced off.
"labels": torch.Tensor of shape (batch_size, max(prompt_and_output_lens) - 1):
shifted input_ids (i.e., the input_ids without the first token).
"response_mask": torch.Tensor of shape (batch_size, max(prompt_and_output_lens) - 1):
a mask on the response tokens in `labels`.
"""
#raise NotImplementedError
input_ids = []
labels = []
response_mask = []
max_lens = 0
for prompt, output in zip(prompt_strs, output_strs):
prompt_token = tokenizer.tokenize(prompt)
m = len(prompt_token)
output_token = tokenizer.tokenize(output)
n = len(output_token)
max_lens = max(max_lens, m + n)
for prompt, output in zip(prompt_strs, output_strs):
prompt_token = tokenizer.encode(prompt)
m = len(prompt_token)
output_token = tokenizer.encode(output)
n = len(output_token)
if m + n < max_lens:
input_id = prompt_token + output_token + [tokenizer.pad_token_id] * (max_lens - 1 - m - n)
lable = input_id[1:] + [tokenizer.pad_token_id]
mask = [False] * (m - 1) + [True] * n + [False] * (max_lens - m - n)
else:
input_id = prompt_token + output_token[:-1]
lable = prompt_token[1:] + output_token
mask = [False] * (m - 1) + [True] * n
input_ids.append(input_id)
labels.append(lable)
response_mask.append(mask)
return {
"input_ids": torch.tensor(input_ids),
"labels": torch.tensor(labels),
"response_mask": torch.tensor(response_mask)
}Logging per-token entropies:在进行强化学习(RL)时,跟踪逐标记熵值通常很有用,可以借此观察模型的预测分布是否变得(过)确信。我们现在将实现这一功能,并比较每种微调方法对模型预测熵的影响。
对于支撑集为 X 的离散分布 p(x),其熵定义为:
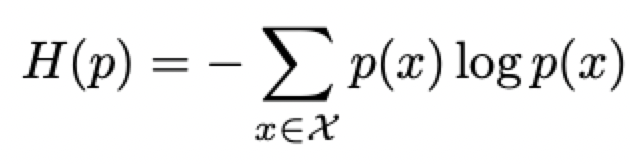
输入logits,输出每个next-token的熵。代码实现:
def run_compute_entropy(logits: torch.Tensor) -> torch.Tensor:
"""Get the entropy of the logits (i.e., entropy of the final dimension)."""
#raise NotImplementedError
log_probs = logits - torch.logsumexp(logits, dim=-1, keepdim=True) # log_softmax(x) = x - logsumexp(x)
probs = torch.exp(log_probs)
entropy = -torch.sum(probs * log_probs, dim=-1)
return entropy从model获得log-probabilities:
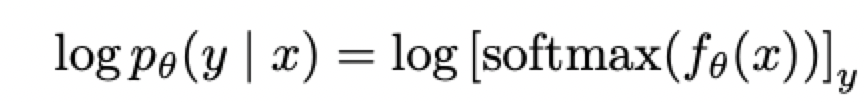
后续SFT和RL都需要用。代码实现:
def run_get_response_log_probs(
model: torch.nn.Module,
input_ids: torch.Tensor,
labels: torch.Tensor,
return_token_entropy: bool,
) -> torch.Tensor:
"""Get the conditional log-probs of the response given the prompt,
and optionally the entropy of the next token predictions.
Args:
model: PreTrainedModel, the model to score.
input_ids: torch.Tensor of shape (batch_size, sequence_length):
the tokenized prompt and output.
labels: torch.Tensor of shape (batch_size, sequence_length):
shifted input_ids.
return_token_entropy: bool, whether to return the entropy of the
next token predictions.
Returns:
dict[str, torch.Tensor]:
"log_probs": torch.Tensor of shape (batch_size, sequence_length):
the conditional log-probs of the response given the prompt.
Note that we have not masked out the token indices corresponding
to the prompt or padding; that is done in the train loop.
"token_entropy": Optional[torch.Tensor] of shape (batch_size, sequence_length):
the entropy of the next token predictions. As with the log-probs,
we have not masked out the token indices corresponding to the prompt
or padding; that is done in the train loop.
"""
#raise NotImplementedError
# 前向传播获取 logits
outputs = model(input_ids)
logits = outputs.logits # shape: (batch_size, seq_len, vocab_size)
# 获取目标 token 的 logits(labels 表示要预测的 token)
# labels 是 shifted input_ids,所以每个位置的 logits 对应预测下一个 token
# 我们只需要 labels 不为 -100 的位置(即 response 部分)
batch_size, seq_len, vocab_size = logits.shape
# 将 logits 和 labels 展平,以便收集对应位置的 logits
logits_flat = logits.reshape(-1, vocab_size) # (batch_size * seq_len, vocab_size)
labels_flat = labels.reshape(-1) # (batch_size * seq_len)
# 创建掩码:只保留 labels 不是 -100 的位置(即需要计算的位置)
mask = labels_flat != -100
# 如果没有任何需要计算的位置,返回全零
if not mask.any():
log_probs = torch.zeros_like(labels, dtype=torch.float)
if return_token_entropy:
token_entropy = torch.zeros_like(labels, dtype=torch.float)
return {"log_probs": log_probs, "token_entropy": token_entropy}
return {"log_probs": log_probs}
# 获取有效位置的 logits
valid_logits = logits_flat[mask] # (num_valid, vocab_size)
valid_labels = labels_flat[mask] # (num_valid,)
# 计算 log_softmax
log_probs_valid = torch.log_softmax(valid_logits, dim=-1) # (num_valid, vocab_size)
# 收集目标 token 的 log probability
target_log_probs = log_probs_valid.gather(
dim=-1, index=valid_labels.unsqueeze(-1)
).squeeze(-1) # (num_valid,)
# 构建完整的 log_probs 张量(与 labels 形状相同)
log_probs = torch.zeros_like(labels, dtype=torch.float)
log_probs.reshape(-1)[mask] = target_log_probs
result = {"log_probs": log_probs}
# 如果需要返回熵
if return_token_entropy:
# 计算熵: -Σ p(x) * log p(x)
#probs = torch.softmax(valid_logits, dim=-1) # (num_valid, vocab_size)
#log_probs_valid_for_entropy = torch.log_softmax(valid_logits, dim=-1)
#entropy_valid = -torch.sum(probs * log_probs_valid_for_entropy, dim=-1) # (num_valid,)
entropy_valid = run_compute_entropy(valid_logits)
# 构建完整的熵张量
token_entropy = torch.zeros_like(labels, dtype=torch.float)
token_entropy.reshape(-1)[mask] = entropy_valid
result["token_entropy"] = token_entropy
return resultSFT微批次训练步骤:在监督微调中,我们最小化的损失是给定提示词时目标输出的负对数似然。为计算该损失,我们需要计算给定提示词时目标输出的对数概率,并对输出中的所有标记求和,同时对提示词内的标记与填充标记进行掩码处理。
我们将为此实现一个辅助函数,该函数在后续强化学习(RL)阶段也会被使用。代码如下:
def run_masked_normalize(
tensor: torch.Tensor,
mask: torch.Tensor,
dim: int | None = None,
normalize_constant: float = 1.0,
) -> torch.Tensor:
"""Sum over a dimension and normalize by a constant,
considering only the elements with mask value 1.
Args:
tensor: torch.Tensor, the tensor to sum and normalize.
mask: torch.Tensor, the mask. We only consider elements
with mask value 1.
dim: int | None, the dimension to sum along before
normalization. If None, sum over all dimensions.
normalize_constant: float, the constant to divide by
for normalization.
Returns:
torch.Tensor, the normalized sum, where masked elements
(mask=0) don't contribute to the sum.
"""
#raise NotImplementedError
masked_tensor = tensor * mask # mask
# 沿指定维度求和
if dim is None:
# 对所有维度求和,返回标量
summed = masked_tensor.sum()
else:
# 对指定维度求和,保持其他维度
summed = masked_tensor.sum(dim=dim)
# 归一化
result = summed / normalize_constant
return result实现SFT的微批次训练步骤,含梯度累积,代码如下:
def run_sft_microbatch_train_step(
policy_log_probs: torch.Tensor,
response_mask: torch.Tensor,
gradient_accumulation_steps: int,
normalize_constant: int | None = 1.0,
) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""Compute the policy gradient loss and backprop its gradients for a microbatch.
"""
#raise NotImplementedError
per_sample_loss = run_masked_normalize(-policy_log_probs, response_mask, 1, normalize_constant)
# 再取 batch 平均
loss = per_sample_loss.mean()
# 调整梯度累积
loss = loss / gradient_accumulation_steps
# 反向传播
loss.backward()
# 计算元数据(用于日志)
metadata = {
"microbatch_loss": loss.item() * gradient_accumulation_steps, # 原始损失(未缩放)
}
return loss, metadataSFT实验
用两张GPU,一个运行policy model,另一个运行vLLM来评估polic(为了简单,这个SFT的实验我直接用LlamaFactory做了,后面的RL再自己手撕..),训练效果如下:
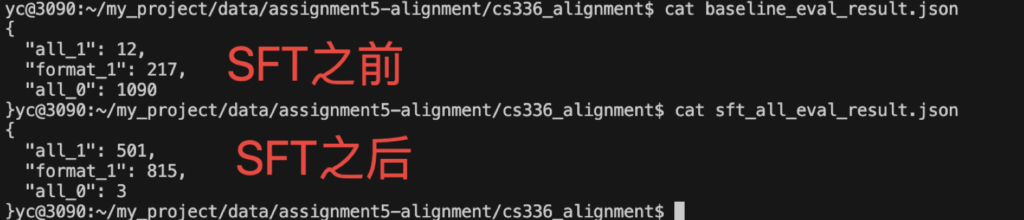
(还有个实验没做,是把训练集中的“坏”数据挑出去,只用好数据做SFT,据说效果比用全数据集更好。)
总结:SFT数据的三大“黄金定律”:
1.微调是“激发”,不是“灌输”。SFT的最佳工作状态,是把模型在预训练阶段(看遍全网数据)就已经学到的知识和能力“提取”出来,而不是试图通过微调教给它全新的知识;
2.强塞正确的知识反而有害。呼应了上一节的结论——如果强行用模型在预训练里没见过的事实(即使这个事实是绝对正确的)去微调它,极容易诱发模型产生“幻觉”,学会胡编乱造;
3.四两拨千斤与长尾效应。对于“立规矩”(如安全护栏、语气风格、指令遵循),极少量的优质数据(比如几百条)就能让模型发生脱胎换骨的改变。但对于处理及其长尾、复杂的各种特定任务,依然是“韩信点兵,多多益善”。
大量微调数据导致的灾难性遗忘如何解决(中期训练):

为什么要引入RL:

1.SFT标注数据贵;2.人的局限性。
验证一个答案的对错,远比从头写一个完美答案要简单得多。
Expert Iteration for GSM8K

(基于上面没做的这个实验的思想)在需要严格正确性验证的推理任务(数学、代码、形式化证明)中,EI依然流行;在通用对话 / 偏好对齐场景,它确实不如 DPO/PPO 流行,因为这些场景更需要人类偏好数据,而 EI 依赖自动奖励函数。
策略梯度入门
OpenAPI、DeepSeek验证了:依托强基模型,结合经过验证的奖励信号开展强化学习(RL),能够显著提升模型的推理能力与整体性能。
LM作为policy
一个参数为θ的因果LM定义了在给定文本下(s_t)下一个token(a_t)的概率分布:
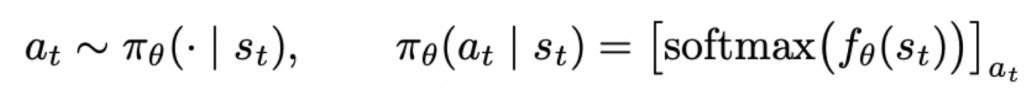
优化这个policy需要以下基础操作:
1.根据策略采样一个动作a_t;
2.计算动作a_t的对数似然:logπθ(at∣st)。
每个episode持续到本次生成结束。
Trajectories
即agent的状态动作序列:
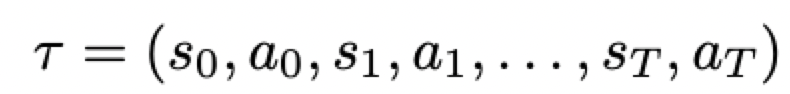
一个trajectory也称一个episode或者rollout,在LLM场景下就是从prompt到生成最后一个token。
Rewards and Return
标准的奖励函数是根据s和a获得的即时奖励,在LLM场景下,在面向可验证领域的强化学习中,通常做法是为中间步骤分配零奖励,而为终止动作分配可验证奖励:

return是一个trajectory的奖励之和,这里没有带折扣系数,这是因为智能体的交互序列存在自然终止节点(文本结束或达到最大生成长度):
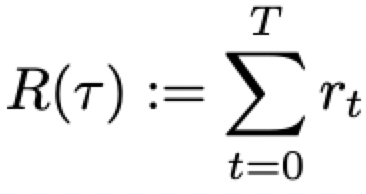
agent的训练目标是最大化期望return:
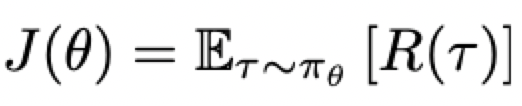
引出一个最优化问题:
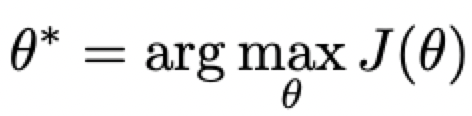
Vanilla Policy Gradient
使用梯度上升来解决这个最优化问题,要计算J相对于theta的梯度,根据策略梯度定理(推导略),有:
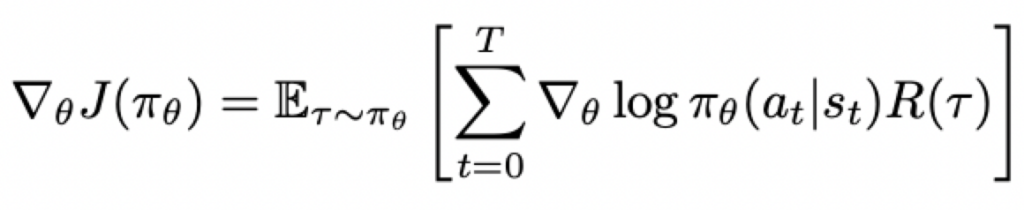
这就是REINFORCE算法中的策略梯度,直觉上,这个梯度会让令return高的action的概率增加,让令return低的action的概率减小。理解如下:


梯度的采样估计:在策略pi_theta下完成N个episode之后取平均得到R,即得到梯度的估计(因为return无法精确计算,这里是通过蒙特卡洛方法来进行估计):
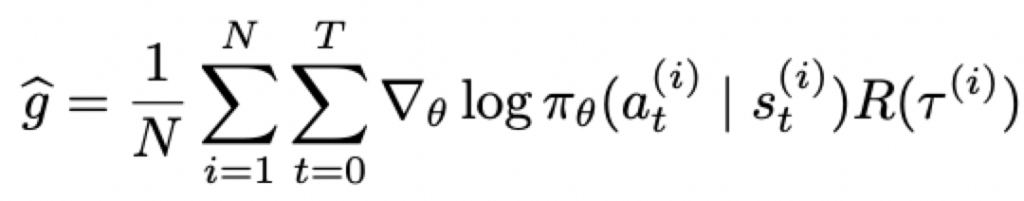
这个梯度被用来更新参数theta:
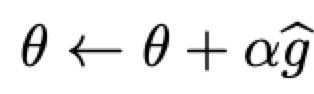
Policy Gradient Baselines
上述梯度估计方法方差比较高(由每个episode的奖励差异较大导致的),缓解的办法是把奖励R减去一个只依赖于状态s的函数b,即:
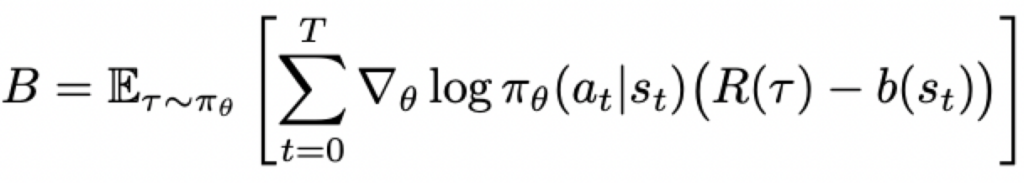
一个常用的基线函数是state value,即:
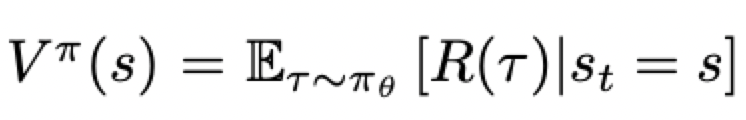
它表示在状态s时,按照策略pi所能得到的return期望。这样R-V就表示实际的trajectory比期望的优势。因为V(s)只和状态s有关,和动作a无关,因此V(s)对theta的梯度是0,所以减去这个基线不会导致梯度的期望变化(可以减小梯度的方差)。
策略梯度损失的含义:
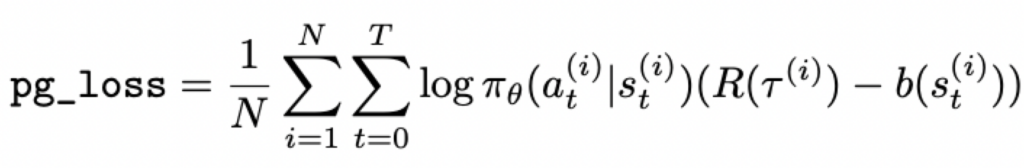
反向传播得到的梯度是 -∇_θ log_prob * A。可以看到,这里的pg_loss只是计算梯度的中介,其值没有绝对含义,不能像交叉熵那样理解成”预测错误程度”。在 RL 中,真正反映模型好坏的是 reward,而不是 pg_loss。
Off-Policy Policy Gradient
上面说的REINFORCE是一个on-policy的策略:behavier policy和target policy是一个策略,即训练数据通过我们正要优化的policy来收集,其算法如下:
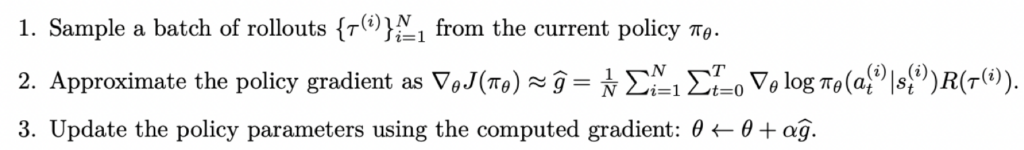
可以看到,我们需要经过一组rollout(完成一次完整的推理过程,生成到最后一个token),才可以做一次参数更新,数据利用很低效。
在off-policy类型的算法中,我们通过与target policy不同的behavier policy来采集训练样本。在PPO、GRPO中,使用旧策略pi_old还采集训练样本,来更新当前策略pi。off-policy的策略梯度如下:
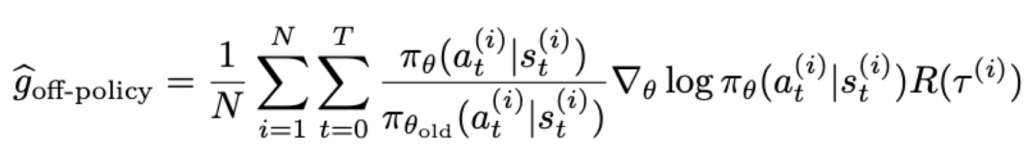
通过重要性采样来进行修正。原理如下:
我们想计算一个关于分布p的期望:
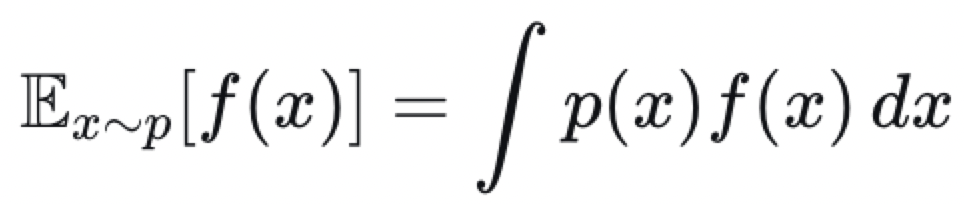
但是通过p进行采样比较困难,只能通过q进行采样,于是:
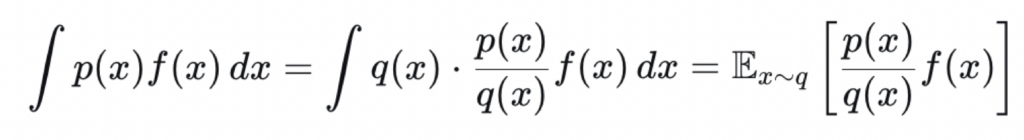
Group Relative Policy Optimization (GRPO)
GRPO Algorithm
优势估计:使用同一个策略对每个问题生成多个答案来计算baseline,相对于PPO减少了Critic网络。DeepSeekMath和DeepSeek R1通过以下方式来计算第i个output的优势:
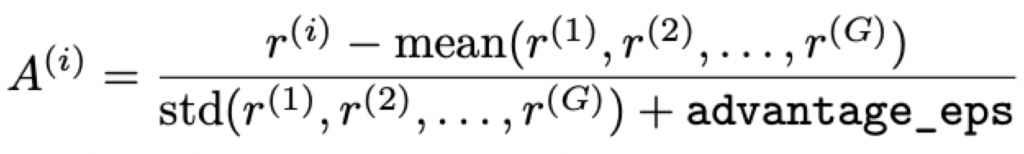
GROP objective:
1.off-policy;2.通过组来计算优势函数;3.使用PPO-Clip损失来优化(Clip的目的是防止新旧策略相差太远,虽然期望可以通过重要性采样来修正,但是方差不能)。
以下是GRPO的一个特例(使用可验证的奖励函数,没有KL散度,没有迭代更新reference和reward模型):

GRPO-Clip objective如下:
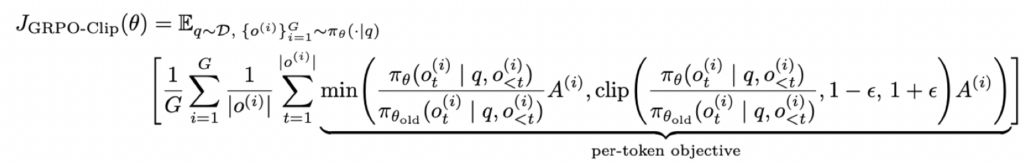
其中的per-token objective可以写成如下更易读的形式,首先定义函数:
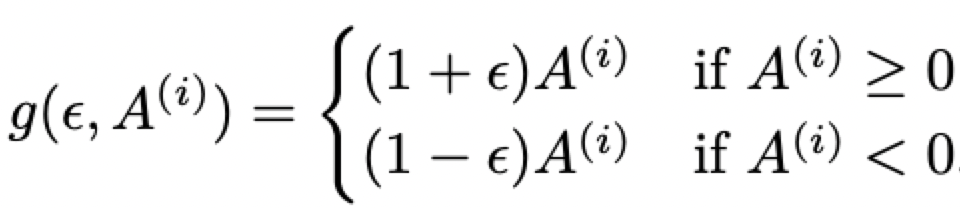
则有:
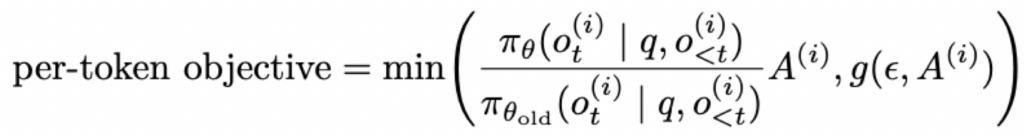
当A为正数时,有:
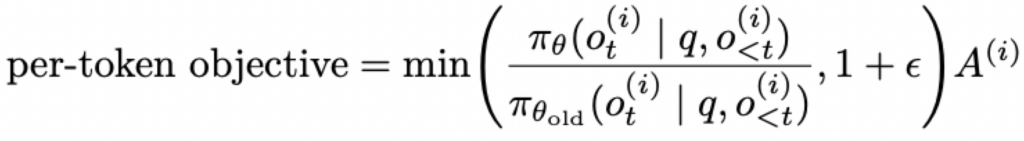
策略尝试增加该token的概率,同时通过clip限制了策略的更新幅度。同理,当A为负数时,clip限制了策略减小该token概率的幅度。
实现GRPO
计算优势:论文Dr. GRPO指出可以不用除以标准差。代码实现:
def run_compute_group_normalized_rewards(
reward_fn: Callable,
rollout_responses: list[str],
repeated_ground_truths: list[str],
group_size: int,
advantage_eps: float,
normalize_by_std: bool,
) -> tuple[torch.Tensor, dict[str, float]]:
"""
Compute rewards for each group of rollout responses,
normalized by the group size.
For more on GRPO, see:
DeepSeekMath: https://arxiv.org/abs/2402.03300
DeepSeek-R1: https://arxiv.org/abs/2501.12948
Args:
reward_fn: Callable[[str, str], dict[str, float]],
scores the rollout responses against the ground truths,
producing a dict with keys
"reward", "format_reward", and "answer_reward".
rollout_responses: list[str], rollouts from the policy.
The length of this list is
`rollout_batch_size = n_prompts_per_rollout_batch * group_size`.
repeated_ground_truths: list[str], the ground truths for the examples.
The length of this list is `rollout_batch_size`,
because the ground truth for each example is repeated `group_size` times.
group_size: int, number of rollouts per group.
advantage_eps: float, epsilon to avoid division by zero
during group normalization.
normalize_by_std: bool, whether to normalize the rewards by
std(rewards).
Returns:
tuple[torch.Tensor, torch.Tensor, dict[str, float]]:
torch.Tensor of shape (rollout_batch_size,):
group-normalized rewards for each rollout response.
torch.Tensor of shape (rollout_batch_size,):
raw rewards for each rollout response.
dict[str, float]: metadata for the rewards of the rollout batch.
You may choose what you wish to log here
(some statistics of the rewards, etc.).
"""
#raise NotImplementedError
n_total = len(rollout_responses)
n_groups = n_total // group_size
#raw_rewards = [reward_fn(resp, gt).get('reward', 0.0) for resp, gt in zip(rollout_responses, repeated_ground_truths)]
raw_rewards = []
nll_mask = []
#my_raw_rewards = []
for resp, gt in zip(rollout_responses, repeated_ground_truths):
result = reward_fn(resp, gt)
raw_rewards.append(result.get('reward', 0.0))
if result.get('reward', 0.0) == 1.0:
nll_mask.append(1)
else:
nll_mask.append(0)
# reward = 1.0
#elif result.get('format_reward', 0.0) == 1.0:
# reward = 0.3
#else:
# reward = 0.0
#my_raw_rewards.append(reward)
raw_rewards_tensor = torch.tensor(raw_rewards, dtype=torch.float32)
nll_mask_tensor = torch.tensor(nll_mask)
#my_raw_rewards_tensor = torch.tensor(my_raw_rewards, dtype=torch.float32)
# 按组归一化
normalized_rewards = []
my_normalized_rewards = []
for g in range(n_groups):
start = g * group_size
end = (g + 1) * group_size
group = raw_rewards[start:end]
mean = sum(group) / group_size
#my_group = my_raw_rewards[start:end]
#my_mean = sum(my_group) / group_size
if normalize_by_std:
if group_size == 1:
std = 1.0
else:
var = sum((x - mean) ** 2 for x in group) / (group_size - 1)
std = (var ** 0.5) + advantage_eps
norm = [(x - mean) / std for x in group]
#my_var = sum((x - my_mean) ** 2 for x in my_group) / (group_size - 1)
#my_std = (my_var ** 0.5) + advantage_eps
#my_norm = [(x - my_mean) / my_std for x in my_group]
else:
norm = [x - mean for x in group]
#my_norm = [x - my_mean for x in my_group]
normalized_rewards.extend(norm)
#my_normalized_rewards.extend(my_norm)
normalized_tensor = torch.tensor(normalized_rewards, dtype=torch.float32)
#my_normalized_tensor = torch.tensor(my_normalized_rewards, dtype=torch.float32)
# 元数据
metadata = {
#"advantages": my_normalized_tensor,
#"raw_rewards": my_raw_rewards_tensor,
"raw_rewards_sum": raw_rewards_tensor.sum(),
"nll_mask": nll_mask_tensor
}
return normalized_tensor, raw_rewards_tensor, metadataNaive策略梯度loss,对于问题q,回答o,每个token的pg_loss为:
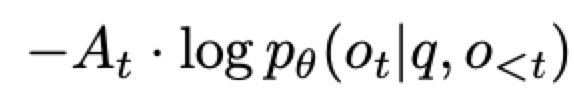
注意,在GRPO场景下,rollout中每个token的优势A是相同的。代码实现:
def run_compute_naive_policy_gradient_loss(
raw_rewards_or_advantages: torch.Tensor,
policy_log_probs: torch.Tensor,
) -> torch.Tensor:
“””Compute policy gradient loss using either raw rewards or advantages.
Args:
raw_rewards_or_advantages: torch.Tensor of shape (batch_size, 1):
the raw rewards or advantages for each rollout response.
policy_log_probs: torch.Tensor of shape (batch_size, sequence_length):
the log-probs of the policy.
Returns:
torch.Tensor of shape (batch_size, sequence_length):
the policy gradient per-token loss.
"""
#raise NotImplementedError
loss = -policy_log_probs * raw_rewards_or_advantages
return loss每个token的GRPO-Clip loss:
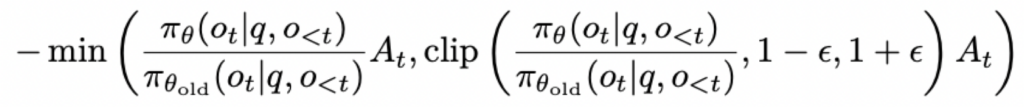
代码实现:
def run_compute_grpo_clip_loss(
advantages: torch.Tensor,
policy_log_probs: torch.Tensor,
old_log_probs: torch.Tensor,
cliprange: float,
response_mask = None
) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""Compute the GRPO-Clip loss.
Args:
advantages: torch.Tensor of shape (batch_size, 1):
the advantages for each rollout response.
policy_log_probs: torch.Tensor of shape (batch_size, sequence_length):
the log-probs of the policy.
old_log_probs: torch.Tensor of shape (batch_size, sequence_length):
the log-probs of the old policy.
cliprange: float, the clip range for the ratio.
Returns:
tuple[torch.Tensor, dict[str, torch.Tensor]]:
torch.Tensor of shape (batch_size, sequence_length):
the GRPO-Clip per-token loss.
dict[str, torch.Tensor]: metadata for the GRPO-Clip loss
(used to compute clip fraction).
"""
#raise NotImplementedError
# ==================== 输入检查 ====================
if torch.isnan(advantages).any():
print("=" * 60)
print("ERROR: advantages contains NaN!")
print(f"policy_log_probs shape: {advantages.shape}")
print(f"policy_log_probs min: {advantages.min()}")
print(f"policy_log_probs max: {advantages.max()}")
print(f"policy_log_probs mean: {advantages.mean()}")
print(f"NaN count: {torch.isnan(advantages).sum().item()}")
print("=" * 60)
sys.exit(1)
if torch.isinf(advantages).any():
print("=" * 60)
print("ERROR: advantages contains Inf!")
print(f"policy_log_probs shape: {advantages.shape}")
print(f"Inf count: {torch.isinf(advantages).sum().item()}")
print("=" * 60)
sys.exit(1)
# 检查 policy_log_probs
if torch.isnan(policy_log_probs).any():
print("=" * 60)
print("ERROR: policy_log_probs contains NaN!")
print(f"policy_log_probs shape: {policy_log_probs.shape}")
print(f"policy_log_probs min: {policy_log_probs.min()}")
print(f"policy_log_probs max: {policy_log_probs.max()}")
print(f"policy_log_probs mean: {policy_log_probs.mean()}")
print(f"NaN count: {torch.isnan(policy_log_probs).sum().item()}")
print("=" * 60)
sys.exit(1)
if torch.isinf(policy_log_probs).any():
print("=" * 60)
print("ERROR: policy_log_probs contains Inf!")
print(f"policy_log_probs shape: {policy_log_probs.shape}")
print(f"Inf count: {torch.isinf(policy_log_probs).sum().item()}")
print("=" * 60)
sys.exit(1)
# 检查 old_log_probs
if torch.isnan(old_log_probs).any():
print("=" * 60)
print("ERROR: old_log_probs contains NaN!")
print(f"old_log_probs shape: {old_log_probs.shape}")
print(f"old_log_probs min: {old_log_probs.min()}")
print(f"old_log_probs max: {old_log_probs.max()}")
print(f"old_log_probs mean: {old_log_probs.mean()}")
print(f"NaN count: {torch.isnan(old_log_probs).sum().item()}")
print("=" * 60)
sys.exit(1)
if torch.isinf(old_log_probs).any():
print("=" * 60)
print("ERROR: old_log_probs contains Inf!")
print(f"old_log_probs shape: {old_log_probs.shape}")
print(f"Inf count: {torch.isinf(old_log_probs).sum().item()}")
print("=" * 60)
sys.exit(1)
log_ratio = policy_log_probs - old_log_probs
ratio = torch.exp(log_ratio)
advantages_expanded = advantages.expand_as(policy_log_probs) # (batch, seq_len)
surr1 = ratio * advantages_expanded
surr2 = torch.clamp(ratio, 1 - cliprange, 1 + cliprange) * advantages_expanded
surr = torch.min(surr1, surr2)
loss = -surr # (batch, seq_len)
if response_mask is None:
response_mask = torch.ones_like(loss)
valid_mask = response_mask.bool()
# metadata
is_clipped = surr2 < surr1 # (batch, seq_len)
# 计算最值
ratio_min = ratio[valid_mask].min().item()
ratio_max = ratio[valid_mask].max().item()
ratio_mean = ratio[valid_mask].mean().item()
adv_min = advantages_expanded[valid_mask].min().item()
adv_max = advantages_expanded[valid_mask].max().item()
surr1_min = surr1[valid_mask].min().item()
surr1_max = surr1[valid_mask].max().item()
# 检查是否有 NaN 或 Inf
has_nan = torch.isnan(ratio[valid_mask]).any().item()
has_inf = torch.isinf(ratio[valid_mask]).any().item()
metadata = {
# 原有
"clip_frac": is_clipped[valid_mask].float().mean().item(),
"mean_ratio": ratio_mean,
"mean_surr1": surr1[valid_mask].mean().item(),
"mean_surr2": surr2[valid_mask].mean().item(),
# 新增:最值
"min_ratio": ratio_min,
"max_ratio": ratio_max,
"min_adv": adv_min,
"max_adv": adv_max,
"min_surr1": surr1_min,
"max_surr1": surr1_max,
# 新增:异常检测
"has_nan": 1.0 if has_nan else 0.0,
"has_inf": 1.0 if has_inf else 0.0,
}
return loss, metadata策略梯度loss wrapper:本实验要对比三个版本的策略梯度,分别是:
(1)no_baseline;(2)reinforce_with_baseline;(3)grpo_clip。
实现一个高效切换的wrapper,代码如下:
def run_compute_policy_gradient_loss(
policy_log_probs: torch.Tensor,
loss_type: str,
raw_rewards: torch.Tensor,
advantages: torch.Tensor,
old_log_probs: torch.Tensor,
cliprange: float,
) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""
Wrapper that delegates to the appropriate policy gradient loss function above.
"""
#raise NotImplementedError
if loss_type == 'reinforce_with_baseline':
return run_compute_naive_policy_gradient_loss(advantages, policy_log_probs), {}
elif loss_type == 'grpo_clip':
return run_compute_grpo_clip_loss(advantages, policy_log_probs, old_log_probs, cliprange)
elif loss_type == 'no_baseline':
return run_compute_naive_policy_gradient_loss(raw_rewards, policy_log_probs), {} Masked mean:为将形状为 (batch_size, sequence_length) 的逐词元损失张量,缩减为单个损失向量(每个样本对应一个标量),我们会在序列维度上计算损失的均值,但仅针对与回复内容对应的索引(即满足 mask[i, j]==1 的词元位置)。
我们支持指定计算均值的维度;若维度参数为空,则对所有掩码元素计算均值。这一特性可用于获取response token的平均逐词元熵、裁剪比例等统计量。
代码实现:
def run_masked_mean(tensor: torch.Tensor, mask: torch.Tensor, dim: int | None = None) -> torch.Tensor:
"""Compute the mean of the tensor along a dimension,
considering only the elements with mask value 1.
Args:
tensor: torch.Tensor, the tensor to compute the mean of.
mask: torch.Tensor, the mask. We only take the mean over
the elements with mask value 1.
dim: int | None, the dimension to compute the mean along.
If None, sum over all non-masked elements and average
by their total count.
Returns:
torch.Tensor, the mean of the tensor along the specified
dimension, considering only the elements with mask value 1.
"""
#raise NotImplementedError
# 将 mask=0 的位置设为 0,不影响求和
masked_tensor = tensor * mask
if dim is None:
# 对所有维度求和,再除以有效元素总数
total_sum = masked_tensor.sum()
valid_count = mask.sum()
else:
# 对指定维度求和,保持其他维度
total_sum = masked_tensor.sum(dim=dim)
valid_count = mask.sum(dim=dim)
return total_sum / valid_countGRPO microbatch train step,代码实现(多实现了一种带nll_loss的情况):
def run_grpo_microbatch_train_step(
policy_log_probs: torch.Tensor,
response_mask: torch.Tensor,
gradient_accumulation_steps: int,
loss_type: Literal["no_baseline", "reinforce_with_baseline", "grpo_clip"],
raw_rewards: torch.Tensor | None = None,
advantages: torch.Tensor | None = None,
old_log_probs: torch.Tensor | None = None,
cliprange: float | None = None,
nll_mask = None
) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""Compute the policy gradient loss and backprop its gradients for a microbatch.
Args:
policy_log_probs: torch.Tensor of shape (batch_size, sequence_length):
the log-probs of the policy.
response_mask: torch.Tensor of shape (batch_size, sequence_length):
the mask for the response.
gradient_accumulation_steps: int, the number of gradient accumulation steps.
loss_type: Literal["no_baseline", "reinforce_with_baseline", "grpo_clip"],
the type of loss function to use.
raw_rewards: torch.Tensor | None, the raw rewards for each rollout response.
Needed for loss_type="no_baseline".
advantages: torch.Tensor | None, the advantages for each rollout response.
Needed for loss_type in {"reinforce_with_baseline", "grpo_clip"}.
old_log_probs: torch.Tensor | None, the log-probs of the old policy.
Needed for loss_type="grpo_clip".
cliprange: float | None, the clip range for the ratio.
Needed for loss_type="grpo_clip".
constant_normalize_factor: int | None, provided if we want to sum over
the sequence dimension and normalize by this constant factor
(as in Dr. GRPO).
Returns:
tuple[torch.Tensor, dict[str, torch.Tensor]]:
the policy gradient loss and its metadata.
"""
#raise NotImplementedError
pg_loss, metadata = run_compute_policy_gradient_loss(policy_log_probs, loss_type, raw_rewards, advantages, old_log_probs, cliprange)
per_batch_loss = run_masked_mean(pg_loss, response_mask, dim=1)
per_batch_loss = torch.nan_to_num(per_batch_loss, nan=0.0) # fix
loss = per_batch_loss.mean()
# 调整梯度累积
ori_loss = loss / gradient_accumulation_steps
loss = ori_loss
# 计算nll loss
if nll_mask is not None:
nll_loss = compute_masked_nll_loss(nll_mask, policy_log_probs, response_mask, gradient_accumulation_steps)
loss += nll_loss
metadata["nll_loss"] = nll_loss.item()
# 反向传播
loss.backward()
return ori_loss, metadata
def compute_masked_nll_loss(
nll_mask: torch.Tensor, # (batch_size, 1)
policy_log_probs: torch.Tensor, # (batch_size, seq_len)
response_mask: torch.Tensor, # (batch_size, seq_len)
gradient_accumulation_steps: int,
) -> torch.Tensor:
# 最终掩码:正确样本 + 有效token
final_mask = nll_mask * response_mask # (batch, seq_len)
# 总有效 token 数量
total_tokens = final_mask.sum()
# 无有效 token 返回 0
if total_tokens < 1:
return torch.tensor(0.0, device=policy_log_probs.device)
# 一步计算:所有有效位置的负对数概率之和 / 总有效token数
loss = (-policy_log_probs * final_mask).sum() / total_tokens
loss = loss / gradient_accumulation_steps
return loss双卡训练(一张rollout+评估,一张训练policy),动态同步模型参数,代码如下:
def init_vllm(model_id: str, device: str, seed: int, gpu_memory_utilization: float = 0.85):
from vllm.model_executor import set_random_seed as vllm_set_random_seed
from unittest.mock import patch
vllm_set_random_seed(seed)
world_size_patch = patch("torch.distributed.get_world_size", return_value=1)
profiling_patch = patch(
"vllm.worker.worker.Worker._assert_memory_footprint_increased_during_profiling",
return_value=None
)
#original_cuda_visible = os.environ.get("CUDA_VISIBLE_DEVICES", None)
#gpu_id = device.split(":")[-1] if ":" in device else device.replace("cuda", "")
#os.environ["CUDA_VISIBLE_DEVICES"] = gpu_id # 只让 vLLM 看见这一张卡
try:
with world_size_patch, profiling_patch:
return LLM(
model=model_id,
device=device,
dtype=torch.bfloat16,
enable_prefix_caching=True,
gpu_memory_utilization=gpu_memory_utilization,
kv_cache_dtype="auto",
tensor_parallel_size=1,
enable_chunked_prefill=True,
max_num_seqs=256,
)
finally:
#if original_cuda_visible is not None:
# os.environ["CUDA_VISIBLE_DEVICES"] = original_cuda_visible
#else:
# os.environ.pop("CUDA_VISIBLE_DEVICES", None)
pass
def load_policy_into_vllm_instance(policy, llm):
state_dict = policy.state_dict()
llm_model = llm.llm_engine.model_executor.driver_worker.model_runner.model
llm_model.load_weights(state_dict.items())
训练循环,代码实现:
from pathlib import Path
import sys
sys.path.append(str(Path(__file__).parent))
from tests.adapters import *
from cs336_alignment.common import *
from transformers import AutoModelForCausalLM, AutoTokenizer
import json
from vllm import LLM, SamplingParams
import random
import os
import argparse
def sample_prompts(dataset, n_prompts):
# 随机抽取 n_prompts 个不同的 prompt
indices = random.sample(range(len(dataset)), n_prompts)
prompts = [dataset[i][0] for i in indices]
ground_truths = [dataset[i][1] for i in indices]
return prompts, ground_truths
def build_train_components(model_path, policy_device, data_path, lr):
policy = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map=policy_device,
#attn_implementation="flash_attention_2",
use_cache=False
)
policy.gradient_checkpointing_enable() # 开启梯度检查点,节省显存
policy.train() # 永远train模式
tokenizer = AutoTokenizer.from_pretrained(model_path)
with open(data_path, "r") as f:
lines = f.readlines()
with open('/home/yc/my_project/data/assignment5-alignment/cs336_alignment/prompts/r1_zero.prompt', 'r') as f:
prompt_base = f.read()
data_list = [json.loads(line) for line in lines]
data = [(prompt_base.format(question=one["question"]), one["answer"]) for one in data_list]
optimizer = torch.optim.AdamW(policy.parameters(), lr=lr, weight_decay=0.0, betas=(0.9, 0.95))
return policy, tokenizer, data, optimizer
def build_eval_components(model_path, vllm_device, data_path):
llm = init_vllm(model_path, vllm_device, 42) # vllm自动保持eval模式
sampling_params = SamplingParams(
temperature=1.0, top_p=1.0, max_tokens=1024, min_tokens=4, stop=["</answer>"], include_stop_str_in_output=True, logprobs=1,
)
with open(data_path, "r") as f:
lines = f.readlines()
prompts = []
ground_truth_list = []
for line in lines:
try:
l_data = json.loads(line.strip())
prompts.append(l_data['question'])
ground_truth_list.append(l_data['answer'])
except:
continue
return llm, prompts, ground_truth_list, sampling_params
def main(args):
assert args.train_batch_size % args.gradient_accumulation_steps == 0, (
"train_batch_size must be divisible by gradient_accumulation_steps"
)
micro_train_batch_size = args.train_batch_size // args.gradient_accumulation_steps # 训练时的最小batch_size
assert args.rollout_batch_size % args.group_size == 0, (
"rollout_batch_size must be divisible by group_size"
)
n_prompts_per_rollout_batch = args.rollout_batch_size // args.group_size # 从数据集中采样,每组采样的数据条数
assert args.train_batch_size >= args.group_size, (
"train_batch_size must be greater than or equal to group_size"
)
# 一次 rollout 采样的数据,需要分成多少个 microbatch 来进行梯度更新
n_microbatches_per_rollout_batch = args.rollout_batch_size // micro_train_batch_size
if not os.path.exists(args.eval_output_dir):
os.makedirs(args.eval_output_dir)
if not os.path.exists(args.model_output_dir):
os.makedirs(args.model_output_dir)
policy_device = f"cuda:{args.policy_device_id}"
vllm_device = f"cuda:{args.vllm_device_id}"
llm, eval_prompts, eval_ground_truth_list, sampling_params = build_eval_components(args.model_path, vllm_device, args.valid_data_path)
policy, tokenizer, train_data, optimizer = build_train_components(args.model_path, policy_device, args.train_data_path, args.lr)
# 记录实验日志文件
log_file = "rl_experiment_log.txt"
log_f = open(log_file, "w")
if log_f:
log_f.write("=" * 80 + "\n")
log_f.write("Experiment Log\n")
log_f.write("=" * 80 + "\n")
log_f.write(f"Command: {args}\n\n")
log_f.flush()
max_eval_reward = 0
# 采样循环
for grpo_step in range(1, args.n_grpo_steps + 1):
prompts, ground_truths = sample_prompts(train_data, n_prompts_per_rollout_batch)
# 扩展group_size倍
prompts_expanded = [prompt for prompt in prompts for _ in range(args.group_size)]
ground_truths_expanded = [ground_truth for ground_truth in ground_truths for _ in range(args.group_size)]
# 采样
outputs = llm.generate(prompts_expanded, sampling_params)
# 提取采样结果
responses = []
old_log_probs_list = []
for output in outputs:
responses.append(output.outputs[0].text)
# 提取每个 token 的 log_prob
token_logprobs = []
for token_logprob in output.outputs[0].logprobs:
if token_logprob:
token_logprobs.append(list(token_logprob.values())[0].logprob)
old_log_probs_list.append(token_logprobs)
advantages, raw_rewards, info = run_compute_group_normalized_rewards(
reward_fn=gsm8k_reward_fn,
rollout_responses=responses,
repeated_ground_truths=ground_truths_expanded,
group_size=args.group_size,
advantage_eps=args.advantage_eps,
normalize_by_std=args.use_std_normalization
)
# 尝试自己设计的奖励机制
#advantages = info["advantages"]
#raw_rewards = info["raw_rewards"]
# 记录训练过程reward
print(f"[rollout] grpo_step:{grpo_step}, rollout_rewards_sum:{info['raw_rewards_sum']}")
if log_f:
log_f.write(f"[rollout] grpo_step:{grpo_step}, rollout_rewards_sum:{info['raw_rewards_sum']}\n")
log_f.flush()
# nll mask
nll_mask = info['nll_mask']
tokenized = run_tokenize_prompt_and_output(
prompts_expanded, # prompt 列表
responses, # 生成的响应
tokenizer
)
input_ids = tokenized["input_ids"]
labels = tokenized["labels"]
response_mask = tokenized["response_mask"]
# 对齐old_log_prob和response_mask
batch_size, max_seq_len = response_mask.shape
assert batch_size == len(old_log_probs_list), (
"old_log_probs_list not match batch_size"
)
# 计算每个样本中 response 部分的起始位置
# response 部分是从第一个 True 开始,到最后一个 True 结束
old_log_probs = []
for i in range(batch_size):
valid = (response_mask[i] == 1).nonzero(as_tuple=True)[0]
if len(valid) == 0:
old_log_probs.append([tokenizer.pad_token_id] * max_seq_len)
else:
start = valid[0].item()
log_padded = [tokenizer.pad_token_id] * max_seq_len
log_padded[start : start + len(old_log_probs_list[i])] = old_log_probs_list[i]
old_log_probs.append(log_padded[:max_seq_len])
old_log_probs = torch.tensor(old_log_probs)
print(f"[rollout] old_log_probs shape:{old_log_probs.shape}")
if torch.isnan(old_log_probs).any():
print(f"[-] old_log_probs have nan!!!")
# 添加这一行,把 NaN 和 Inf 都变成 0
old_log_probs = torch.nan_to_num(old_log_probs, nan=0.0, posinf=0.0, neginf=0.0)
# train
optimizer.zero_grad()
input_ids = input_ids.to(device=policy_device)
labels = labels.to(device=policy_device)
response_mask = response_mask.to(device=policy_device)
advantages = advantages.to(device=policy_device)
old_log_probs = old_log_probs.to(device=policy_device)
raw_rewards = raw_rewards.to(device=policy_device)
nll_mask = nll_mask.to(device=policy_device)
# 每次rollout的更新epoch数
for _ in range(args.epochs_per_rollout_batch):
indices = torch.arange(args.rollout_batch_size)
accumulated_loss = 0.0
for micro_idx in range(n_microbatches_per_rollout_batch):
start = micro_idx * micro_train_batch_size
end = start + micro_train_batch_size
micro_indices = indices[start:end]
# 获取 microbatch 数据
mb_input_ids = input_ids[micro_indices]
mb_labels = labels[micro_indices]
mb_response_mask = response_mask[micro_indices]
mb_advantages = advantages[micro_indices]
mb_old_log_probs = old_log_probs[micro_indices]
mb_raw_rewards = raw_rewards[micro_indices]
mb_nll_mask = nll_mask[micro_indices]
# 当前策略采样
current_output = run_get_response_log_probs(
model=policy,
input_ids=mb_input_ids,
labels=mb_labels,
return_token_entropy=False
)
mb_policy_log_probs = current_output["log_probs"]
loss, train_info = run_grpo_microbatch_train_step(
policy_log_probs=mb_policy_log_probs,
response_mask=mb_response_mask,
gradient_accumulation_steps=args.gradient_accumulation_steps,
loss_type=args.loss_type,
raw_rewards=mb_raw_rewards.unsqueeze(1),
advantages=mb_advantages.unsqueeze(1),
old_log_probs=mb_old_log_probs,
cliprange=args.cliprange,
#nll_mask=mb_nll_mask.unsqueeze(1),
)
print(f"[Training] grpo_step:{grpo_step}, micro_idx:{micro_idx + 1}, loss:{loss.item()}, info:{train_info}")
if log_f:
log_f.write(f"[Training] grpo_step:{grpo_step}, micro_idx:{micro_idx + 1}, loss:{loss.item()}, info:{train_info}\n")
log_f.flush()
accumulated_loss += loss.item() * args.gradient_accumulation_steps
if (micro_idx + 1) % args.gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(
policy.parameters(), args.clip_grad_norm
)
optimizer.step()
optimizer.zero_grad()
print(f"[Training] grpo_step:{grpo_step}, updated policy, accumulated_loss:{accumulated_loss}")
if log_f:
log_f.write(f"[Training] grpo_step:{grpo_step}, updated policy, accumulated_loss:{accumulated_loss}\n")
log_f.flush()
# 同步策略
load_policy_into_vllm_instance(policy, llm)
print(f"loaded new policy")
# 评估策略
if grpo_step % args.eval_steps == 0:
print(f"[Eval] grpo_step:{grpo_step}, start eval")
eval_reward = evaluate_vllm(
vllm_model=llm,
reward_fn=gsm8k_reward_fn,
prompts=eval_prompts,
eval_sampling_params=sampling_params,
ground_truth_list=eval_ground_truth_list,
output_path=f"{args.eval_output_dir}/grpo_step{grpo_step}"
)
if log_f:
log_f.write(f"[Eval] grpo_step: {grpo_step},eval_reward: {eval_reward}\n")
log_f.flush()
# 保存最佳模型
if eval_reward > max_eval_reward:
max_eval_reward = eval_reward
save_path = f"{args.model_output_dir}/best_rl_model"
policy.save_pretrained(save_directory=save_path)
tokenizer.save_pretrained(save_directory=save_path)
print(f"best_rl_model saved, grpo_step:{grpo_step}")
print(f"[Eval] eval done")
# 保存最终模型
save_path = f"{args.model_output_dir}/final_rl_model"
policy.save_pretrained(save_directory=save_path)
tokenizer.save_pretrained(save_directory=save_path)
print(f"final_rl_model saved")
if log_f:
log_f.write("\n" + "=" * 80 + "\n")
log_f.write("Training completed\n")
log_f.write(f"Total grpo_steps: {grpo_step}\n")
log_f.close()
print("Training finished.")
print(f"Total grpo_steps: {grpo_step}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--n_grpo_steps", type=int, default=200)
parser.add_argument("--lr", type=float, default=1e-5)
parser.add_argument("--advantage_eps", type=float, default=1e-6)
parser.add_argument("--rollout_batch_size", type=int, default=256)
parser.add_argument("--group_size", type=int, default=8)
parser.add_argument("--epochs_per_rollout_batch", type=int, default=1)
parser.add_argument("--train_batch_size", type=int, default=256)
parser.add_argument("--gradient_accumulation_steps", type=int, default=128)
parser.add_argument("--loss_type", type=str, default="reinforce_with_baseline")
parser.add_argument("--use_std_normalization", type=bool, default=True)
parser.add_argument("--eval_steps", type=int, default=5)
parser.add_argument("--clip_grad_norm", type=float, default=1.0)
parser.add_argument("--cliprange", type=float, default=0.2)
parser.add_argument("--eval_output_dir", type=str, default="./eval_output")
parser.add_argument("--model_output_dir", type=str, default="./model_output")
parser.add_argument("--model_path", type=str, default="/home/yc/my_project/data/assignment5-alignment/models/Qwen2.5-Math-1.5B")
parser.add_argument("--train_data_path", type=str, default="/home/yc/my_project/data/assignment5-alignment/data/gsm8k/train.jsonl")
parser.add_argument("--valid_data_path", type=str, default="/home/yc/my_project/data/assignment5-alignment/data/gsm8k/test.jsonl")
parser.add_argument("--policy_device_id", type=str, default="1")
parser.add_argument("--vllm_device_id", type=str, default="0")
args = parser.parse_args()
main(args)
我一开始在SFT之后的模型上开展强化学习,发现性能并没有继续提升。作业文档里解释说是因为模型不够大,不能展现出SFT之后继续进行RL的优势。于是我直接在Qwen2.5-1.5B-Base基础模型上开展强化学习(上面代码中默认的超参数),发现效果反而超过了SFT之后的模型效果:
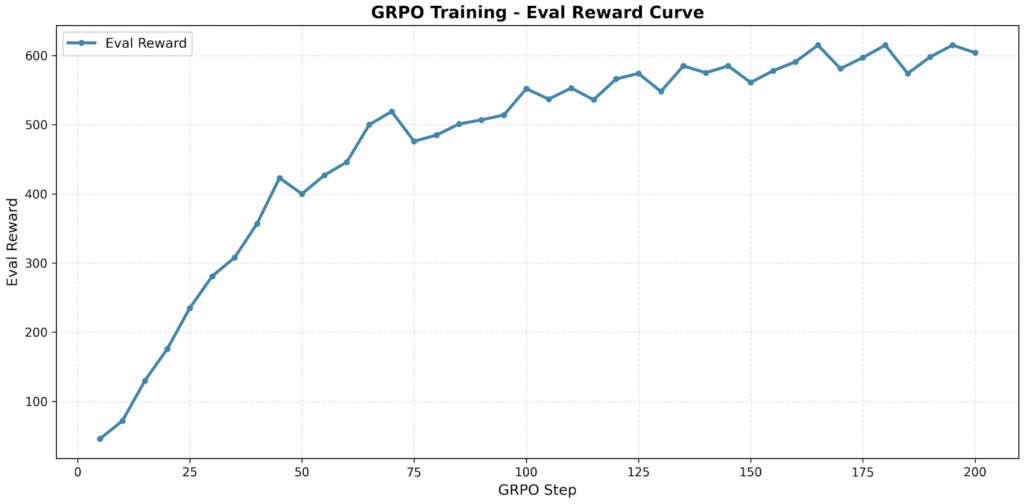
这个Eval Reward就是测试集上格式和答案都正确的结果数量,可以看到,在grpo_step到70步以后,就达到了SFT训练1个epoch的效果;在grpo_step到200步时,奖励稳定在600左右,比SFT模型的结果多了100。