核心问题:给定用于训练大语言模型的计算预算 C,如何选择超参数(模型大小、训练 token 数量等)才能使训练损失最小?
对于计算量 C ,模型参数量 N 和数据集大小 D ,当不受其他两个因素制约时,模型性能 L 与每个因素都呈现幂律关系:
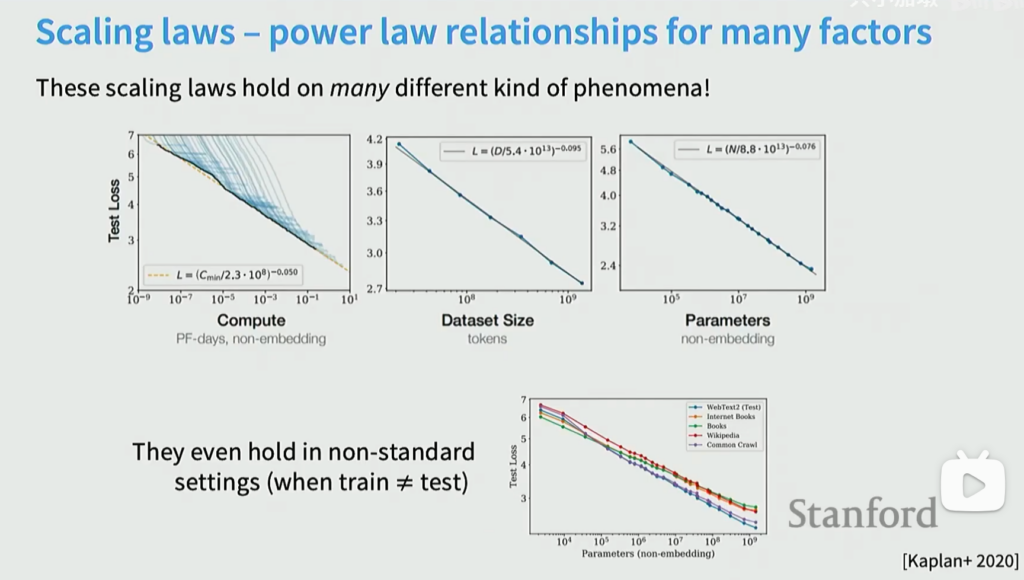
基于等计算量(IsoFLOPs)曲线的Scaling Laws
回顾一下:在包含 D 个 token 的数据集上训练一个参数量为 N 的 Transformer 模型,其计算开销近似为 C=6ND。即:对于每个计算预算 C,在该预算下训练不同大小 N 的语言模型(其中数据量 D=C/(6N)),并得到最终训练损失 L。这会得到一组计算量 Ci 相同、但模型大小 Nij 不同的实验结果。
Hoffmann 等人(2022)通过实验观察到:在固定计算预算 C_i 下,最终训练损失 L_ij 与模型大小 N_ij 之间呈现二次关系。直观理解如下:
当 N_i 极小时,无论投入多少计算量,模型都无法拟合数据,因此该区间内的最终训练损失很高。
随着模型大小增加,训练损失平稳下降;直到某一临界点,模型变得过大,在 C 次 FLOPs 内无法执行足够的梯度步骤来有效训练(极端情况:当 N_i→∞ 时,即使只执行一步梯度更新也会超出预算 C,训练会在极高损失处停止)。
求解Scaling Laws的流程包括:
对每个 C_i 确定最优模型大小与数据大小,然后拟合一个幂律,用于在给定目标计算预算 C(通常大于已有实验预算)时预测最优的 N 和 D。
为拟合幂律,我们利用每组计算预算 C_i 对应的实验结果(即其 “IsoFLOPs 曲线”),找到使训练损失最小的模型大小 N_opt(C_i)。这一过程得到一系列点对 ⟨C_i,N_opt(C_i)⟩(数据量 D_opt 同理)。我们用这些点拟合幂律关系:
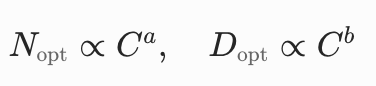
并利用它们将计算最优的模型大小与数据大小外推到目标计算预算上。