CS336作业5——Alignment and Reasoning RL:http://www.sfishlost.com/2026/03/28/cs336work5/
实现BPE
直接在unicode码位上训练tokenizers很难,因为词表会非常大,并且稀疏(因为很多字符很罕见),需要用unicode编码把字符转化为字节序列(utf-8最常用,相比utf-16和utf-32,utf-8的字节序列最短)。
虽然byte-level的tokenization可以缓解word-level词汇量不足的问题,但是也增加了序列的长度,增加了模型的处理时间,此外,对字节序列进行语言建模很困难,因为较长的输入序列会在数据中产生长期依赖关系。
subword tokenization介于byte-level和word-level之间,它会将频繁出现的子词统一看作1个token。BPE即典型的subword tokenization。
BPE tokenizer 训练过程包括三个主要步骤:
1.vocabulary initialization:即token到id的映射。byte-level的BPE,词表初始化的时候仅包括256个可能的byte。
2.pre-tokenization:如果直接在原始语料库上运行BPE算法,需要反复扫描整个文本,计算字符对的频率,这非常低效。可以先对语料库进行”粗粒度”的分词,将文本分成较大的单元(如单词)。
例如原始BPE直接使用空白字符进行预分词,GPT-2使用以下正则表达式进行预分词:PAT = r”””‘(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?\s\p{L}\p{N}+|\s+(?!\S)|\s+”””。
3.Compute BPE merges:合并频率最高的pair,将其添加到词表中。如果有很多组频率最高的则按照字典序合并最大的pair。
特殊token:例如<|endoftext|> 应作为一个固定的token,直接初始化到词表中,不需要合并或者拆分。
代码实现:
def run_train_bpe(
input_path: str | os.PathLike,
vocab_size: int,
special_tokens: list[str],
**kwargs,
) -> tuple[dict[int, bytes], list[tuple[bytes, bytes]]]:
"""Given the path to an input corpus, run train a BPE tokenizer and
output its vocabulary and merges.
Args:
input_path (str | os.PathLike): Path to BPE tokenizer training data.
vocab_size (int): Total number of items in the tokenizer's vocabulary (including special tokens).
special_tokens (list[str]): A list of string special tokens to be added to the tokenizer vocabulary.
These strings will never be split into multiple tokens, and will always be
kept as a single token. If these special tokens occur in the `input_path`,
they are treated as any other string.
Returns:
tuple[dict[int, bytes], list[tuple[bytes, bytes]]]:
vocab:
The trained tokenizer vocabulary, a mapping from int (token ID in the vocabulary)
to bytes (token bytes)
merges:
BPE merges. Each list item is a tuple of bytes (<token1>, <token2>),
representing that <token1> was merged with <token2>.
Merges are ordered by order of creation.
"""
#raise NotImplementedError
import regex as re
with open(input_path, "rb") as f:
corpus = f.read()
# init vocab
special_tokens = [s.encode('utf-8') for s in special_tokens]
i_vocab = special_tokens.copy()
i_vocab += [bytes([i]) for i in range(256)]
# pre-tokenization
delimiter_pattern = b"|".join([re.escape(token) for token in special_tokens])
chunks = re.split(delimiter_pattern, corpus)
PAT = br"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
freq_dict = {}
for c in chunks:
for one in re.finditer(PAT, c):
one = one.group(0)
one_tuple = tuple([bytes([byte]) for byte in one])
if one_tuple not in freq_dict:
freq_dict[one_tuple] = 1
else:
freq_dict[one_tuple] += 1
cache_dict = {}
pb_to_pair = {}
pair_to_ori = {}
for k, v in freq_dict.items():
ll = list(k)
pair_list = [(ll[i], ll[i + 1]) for i in range(len(ll) - 1)]
for p in pair_list:
p_b = p[0] + p[1]
pb_to_pair[p_b] = p
if p_b not in cache_dict:
cache_dict[p_b] = v
else:
cache_dict[p_b] += v
if p_b not in pair_to_ori:
pair_to_ori[p_b] = [k]
else:
pair_to_ori[p_b].append(k)
# merge loop
now_size = len(i_vocab)
merges = []
while now_size < vocab_size:
#max_pb = max(cache_dict, key=cache_dict.get)
max_freq = max(cache_dict.values())
best_pairs = [pb for pb in cache_dict if cache_dict[pb] == max_freq]
# 按照第一个token的字典序降序排序
best_pairs.sort(key=lambda pb: (pb_to_pair[pb][0], pb_to_pair[pb][1]), reverse=True)
max_pb = best_pairs[0]
max_pair = pb_to_pair[max_pb]
# merge
new_freq = {}
need_del_k = []
for k in pair_to_ori[max_pb]:
if k not in freq_dict:
continue
v = freq_dict[k]
k_list = []
i = 0
while i < len(k):
if i + 1 < len(k) and max_pair == (k[i], k[i + 1]):
k_list.append(k[i] + k[i + 1])
i += 2
else:
k_list.append(k[i])
i += 1
# update freq_dict
freq_dict[tuple(k_list)] = v
del freq_dict[k]
# update cache
ll = list(k)
pair_list = [(ll[i], ll[i + 1]) for i in range(len(ll) - 1)]
for p in pair_list:
p_b = p[0] + p[1]
cache_dict[p_b] -= v
new_pair_list = [(k_list[i], k_list[i + 1]) for i in range(len(k_list) - 1)]
for p in new_pair_list:
p_b = p[0] + p[1]
if p_b not in cache_dict:
cache_dict[p_b] = v
else:
cache_dict[p_b] += v
pb_to_pair[p_b] = p
if p_b not in pair_to_ori:
pair_to_ori[p_b] = [tuple(k_list)]
else:
pair_to_ori[p_b].append(tuple(k_list))
# record
merges.append(max_pair)
i_vocab.append(max_pb)
now_size += 1
# done
vocab = {}
for i in range(len(i_vocab)):
vocab[i] = i_vocab[i]
return vocab, merges
使用BPE
编码步骤:
1.Pre-tokenize:首先,把原始句子表示成一系列utf-8字节序列(unicode编码),后续根据词表来合并每个字节序列内部的字节(不会跨pre-token分隔符);
2.Apply the merges:然后,采用在 BPE 训练期间创建的词汇元素合并序列,并按照相同的创建顺序将其应用于我们的pre-tokens。
注意处理special tokens,考虑使用分块的方式固定内存使用(而不是让空间复杂度为O(n))。
解码:
查词表,拼接,然后unicode解码为字符串即可。
如果输入的ID没有对应有效的unicode字符,则用U+FFFD代替(解码时使用errors=’replace’参数进行处理)。
代码实现:
class Tokenizer:
def __init__(self, vocab, merges, special_tokens=None):
self.vocab = vocab
self.vocab_reverse = {v: k for k, v in self.vocab.items()}
self.merges = merges
self.vocab_size = len(self.vocab_reverse)
self.special_tokens = []
if special_tokens:
self.special_tokens = [s.encode('utf-8') for s in special_tokens]
for st in self.special_tokens:
if st not in self.vocab_reverse:
self.vocab_reverse[st] = self.vocab_size
self.vocab[self.vocab_size] = st
self.vocab_size += 1
@classmethod
def from_files(cls, vocab_filepath, merges_filepath, special_tokens=None):
import json
with open(vocab_filepath, 'r') as f1:
vocab = json.loads(f1.read())
with open(merges_filepath, 'r') as f2:
merges = json.loads(f2.read())
p = cls(vocab, merges, special_tokens)
return p
def encode(self, text: str) -> list[int]:
import regex as re
b_text = text.encode('utf-8')
# Pre-tokenize
if self.special_tokens:
delimiter_pattern = b"|".join([re.escape(token) for token in self.special_tokens])
#chunks = re.split(delimiter_pattern, text)
chunks = re.split(f'({delimiter_pattern.decode("utf-8")})', b_text.decode('utf-8'))
chunks = [c.encode('utf-8') for c in chunks]
else:
chunks = [b_text]
# 处理连续分隔符问题
indices = [index for index, value in enumerate(chunks) if value == b'']
for i in indices:
try:
if chunks[i - 1] + chunks[i + 1] in self.vocab_reverse:
chunks = chunks[:i - 1] + [chunks[i - 1] + chunks[i + 1]] + [b'sfishgogogo', b'sfishgogogo'] + chunks[i + 2:]
except:
continue
chunks = [item for item in chunks if item != b'sfishgogogo']
PAT = br"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
result = []
for c in chunks:
if c in self.special_tokens:
result.append(self.vocab_reverse[c])
else:
# Apply the merges
for one in re.finditer(PAT, c):
one = one.group(0)
b_list = [bytes([byte]) for byte in one]
while True:
pair_list = [(b_list[i], b_list[i + 1]) for i in range(len(b_list) - 1)]
p_index = self.vocab_size + 1
merge_pair = None
for bp in pair_list:
try:
bp_index = self.merges.index(bp)
if bp_index < p_index:
merge_pair = bp
p_index = bp_index
except:
pass
if not merge_pair:
break
else:
i = 0
k = b_list
k_list = []
while i < len(k):
if i + 1 < len(k) and merge_pair == (k[i], k[i + 1]):
k_list.append(k[i] + k[i + 1])
i += 2
else:
k_list.append(k[i])
i += 1
b_list = k_list.copy()
for bp in b_list:
result.append(self.vocab_reverse[bp])
return result
def encode_iterable(self, iterable: Iterable[str]) -> Iterable[int]:
if self.special_tokens:
leftover = "" # 用于缓存跨行的分隔符部分
for text in iterable:
current_text = leftover + text # 合并剩余部分和当前行
leftover = "" # 重置缓存
while current_text:
# 查找当前文本中的分隔符
pos = -1
for st in self.special_tokens:
pos = current_text.encode('utf-8').find(st)
if pos != -1:
break
if pos != -1:
# 处理分隔符之前的文本
before_split = current_text.encode('utf-8')[:pos].decode('utf-8')
token_ids = self.encode(before_split)
for token_id in token_ids:
yield token_id
# 处理分隔符本身
yield self.vocab_reverse[st]
# 处理分隔符之后的文本
current_text = current_text.encode('utf-8')[pos + len(st):].decode('utf-8') # 移除已经处理的分隔符及其之前的文本
else:
# 如果没有找到分隔符,缓存当前行的尾部并继续读取下一行
leftover = current_text
break
if leftover:
token_ids = self.encode(leftover)
for token_id in token_ids:
yield token_id
else:
for text in iterable:
token_ids = self.encode(text)
for token_id in token_ids:
yield token_id
def decode(self, ids: list[int]):
b_text = b''
for id in ids:
b_text += self.vocab[id]
return b_text.decode('utf-8', errors='replace')Transformer Language Model Architecture
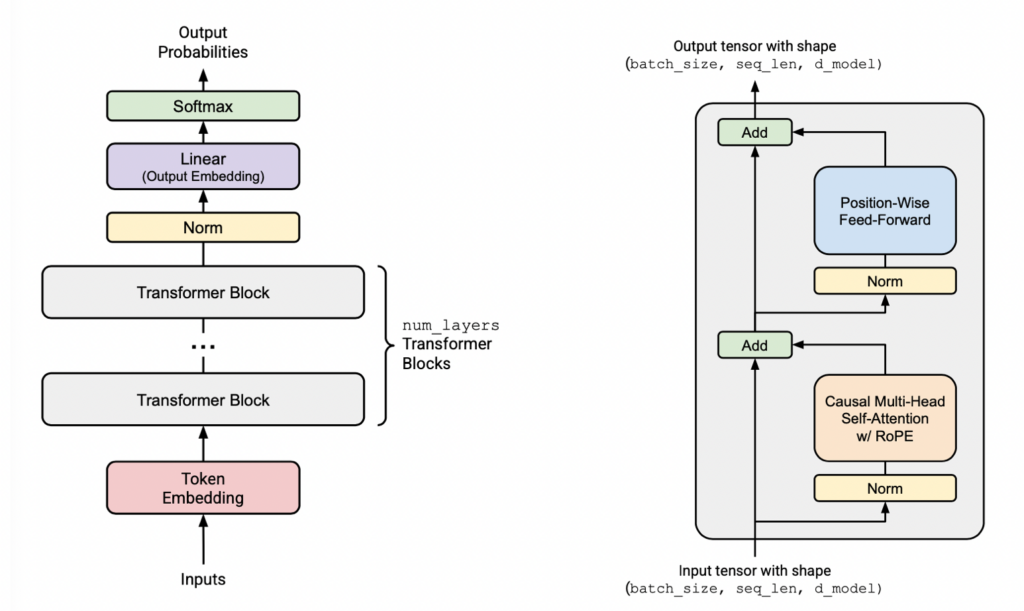
输入:(batch_size, sequence_length)
输出:(batch_size, sequence_length, vocab_size)
在训练语言模型时,我们使用这些下一个word预测来计算实际下一个word与预测下一个word之间的交叉熵损失。在推理过程中从语言模型生成文本时,我们从最后的时间步(即序列中的最后一项)获取预测的下一个word分布来生成序列中的下一个 token(例如,取概率最高的 token、从分布中采样等),将生成的 token 添加到输入序列,然后重复。
Token Embeddings:
把token id序列转化为d_model维的稠密向量序列。
输入维度:(batch_size, sequence_length)
输出维度:(batch_size, sequence_length, d_model)
Pre-norm Transformer Block:
嵌入层之后,标准的decoder-only Transformer语言模型由num_layers层Transformer “blocks”组成。
Transformer block的输入维度:(batch_size, sequence_length, d_model)
Transformer block的输出维度:(batch_size, sequence_length, d_model)
每个block会聚合整个序列的信息(通过自注意力机制),并对其进行非线性变换(通过前馈层)。
Output Normalization and Embedding:
最后一个Transformer block后,需要layer normalization来归一化输出,之后对Transformer blocks的输出做一个线性变换来预测下一个token的logits。
Linear Module
代码实现:
class Linear(nn.Module):
def __init__(self, in_features, out_features, device=None, dtype=None):
super(Linear, self).__init__()
self.device = device
self.dtype = dtype
self.in_features = in_features
self.out_features = out_features
# 计算标准差 std = sqrt(2 / (d_in + d_out))
std = math.sqrt(2.0 / (self.in_features + self.out_features))
# 计算截断区间
a, b = -3 * std, 3 * std
# 初始化权重,使用 trunc_normal_ 来实现
self.weight = nn.Parameter(torch.empty(self.out_features, self.in_features, dtype=self.dtype, device=self.device))
nn.init.trunc_normal_(self.weight, mean=0.0, std=std, a=a, b=b) # 截断正态分布初始化权重
def forward(self, x: torch.Tensor) -> torch.Tensor:
return torch.matmul(x, self.weight.T)Embedding Module
代码实现:
class Embedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim, device=None, dtype=None):
super(Embedding, self).__init__()
self.vocab_size = num_embeddings
self.d_model = embedding_dim
self.device = device
self.dtype = dtype
# 初始化权重,使用 trunc_normal_ 来实现
self.embedding_matrix = nn.Parameter(torch.empty(self.vocab_size, self.d_model, dtype=self.dtype, device=self.device))
nn.init.trunc_normal_(self.embedding_matrix, mean=0.0, std=1, a=-3, b=3) # 截断正态分布初始化权重
def forward(self, token_ids: torch.Tensor) -> torch.Tensor:
# 通过索引方式从嵌入矩阵中选择对应的嵌入向量
# 返回形状为 (batch_size, sequence_length, d_model) 的张量
return self.embedding_matrix[token_ids]Pre-Norm Transformer Block
Pre-norm的一个直觉是:从输入嵌入到 Transformer 的最终输出,存在一个干净的“残差流”,没有任何标准化,这是为了改善梯度流。

代码实现:
class RMSNorm(nn.Module):
def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype=None):
super(RMSNorm, self).__init__()
self.d_model = d_model
self.eps = eps
self.device = device
self.dtype = dtype
# 可训练的缩放因子 gamma,初始化为 1
self.gamma = nn.Parameter(torch.ones(d_model, dtype=self.dtype, device=self.device))
def forward(self, x: torch.Tensor) -> torch.Tensor:
in_dtype = x.dtype
x = x.to(torch.float32) # 防止数值溢出
# 计算 RMS
rms = torch.sqrt(torch.mean(x ** 2, dim=-1, keepdim=True) + self.eps)
# 标准化
x_normalized = x / rms
# 使用缩放因子进行缩放
result = self.gamma * x_normalized
return result.to(in_dtype)Position-Wise Feed-Forward Network
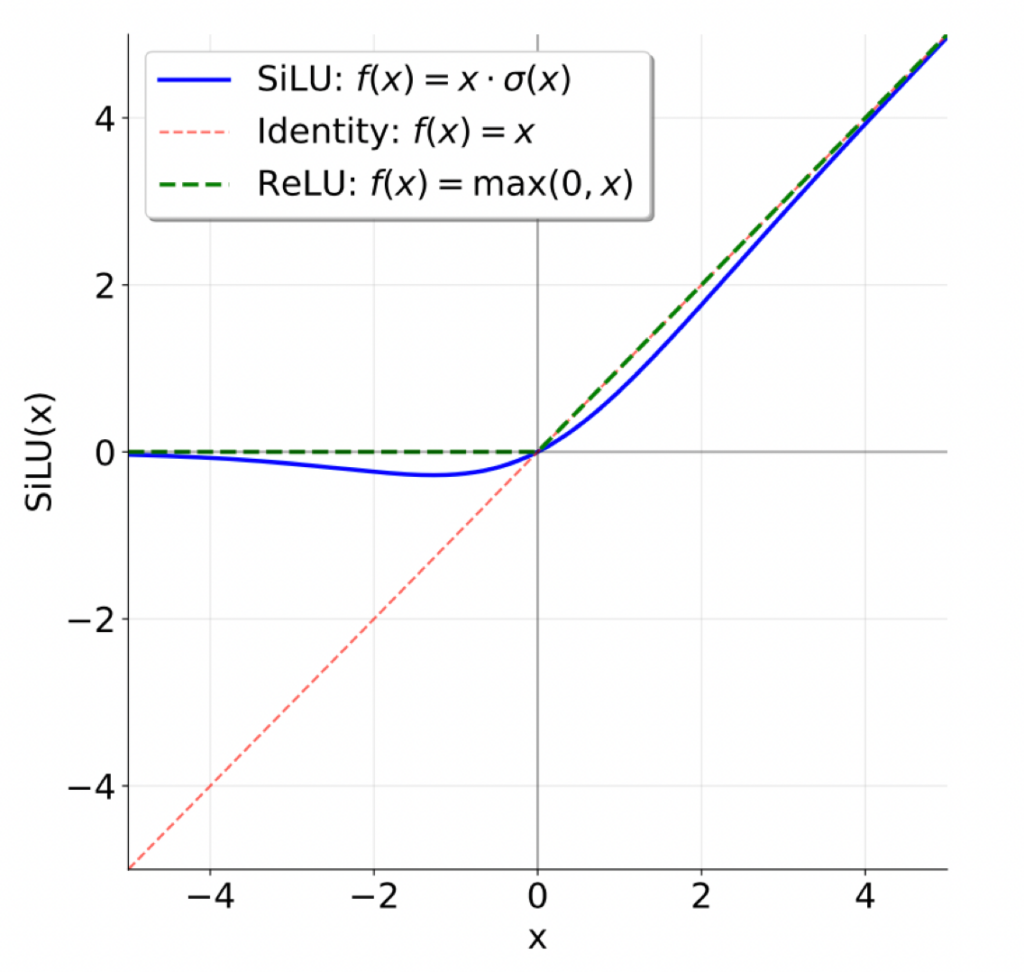
SiLU和ReLU的对比:
Gated Linear Units(GLUs):
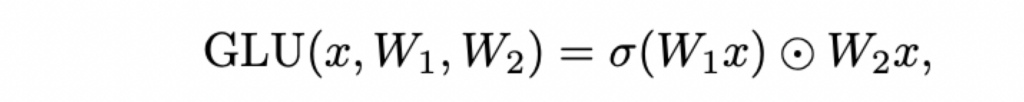
⊙表示逐元素相乘。
GLUs的意义:通过为梯度提供线性路径,同时保留非线性能力,来减少深度架构的梯度消失问题。
SwiGLU:
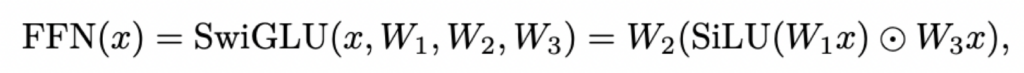
其中,x维度为d_model,W1和W3维度为(d_ff, d_model),W2维度为(d_model, d_ff),通常来说,d_ff = (8/3)d_model。
代码实现:
class SwiGLU(nn.Module):
def __init__(self, d_model, d_ff, device=None, dtype=None):
super(SwiGLU, self).__init__()
self.d_model = d_model
self.d_ff = d_ff
self.device = device
self.dtype = dtype
self.w1 = Linear(in_features=self.d_model, out_features=self.d_ff)
self.w3 = Linear(in_features=self.d_model, out_features=self.d_ff)
self.w2 = Linear(in_features=self.d_ff, out_features=self.d_model)
def _silu(self, x):
return x * torch.sigmoid(x)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.w2(self._silu(self.w1(x)) * self.w3(x))Relative Positional Embeddings(RoPE)
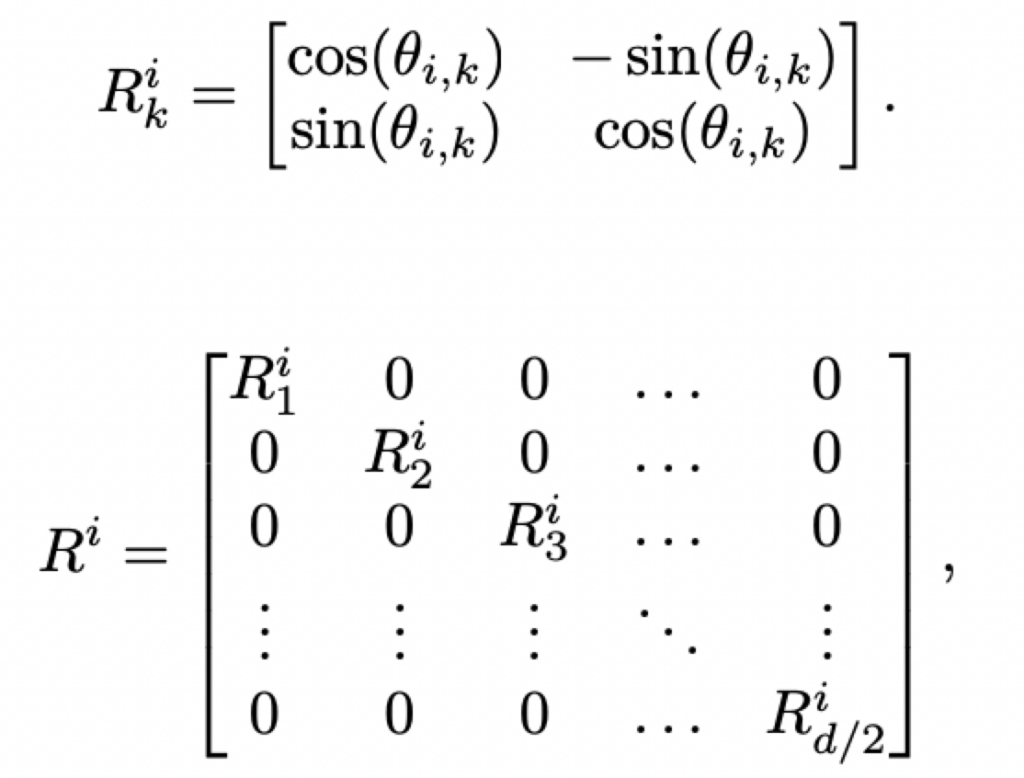
其中0表示一个2×2的零矩阵。
代码实现:
class RotaryPositionalEmbedding(nn.Module):
def __init__(self, theta: float, d_k: int, max_seq_len: int, device=None):
super(RotaryPositionalEmbedding, self).__init__()
self.theta = theta
self.d_k = d_k
self.max_seq_len_cached = max_seq_len
self.device = device
inv_freq = 1.0 / (self.theta ** (torch.arange(0, self.d_k, 2).float().to(self.device) / self.d_k)) # (d_k // 2,)
self.register_buffer("inv_freq", inv_freq, persistent=False)
t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
freqs = torch.einsum("i,j->ij", t, self.inv_freq) # (max_seq_len_cached, d_k // 2)
self.register_buffer("cos_cached", torch.cos(freqs), persistent=False)
self.register_buffer("sin_cached", torch.sin(freqs), persistent=False)
def forward(self, x: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:
batch_size, seq_len, d_k = x.shape
# 检查输入的 seq_len 是否超出了缓存的最大序列长度
if seq_len > self.max_seq_len_cached:
# 更新 max_seq_len_cached 为当前的 seq_len
self.max_seq_len_cached = seq_len
# 计算新的频率矩阵
t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype) # [max_seq_len_cached]
freqs = torch.einsum("i,j->ij", t, self.inv_freq) # [max_seq_len_cached, d_k / 2]
self.register_buffer("cos_cached", torch.cos(freqs), persistent=False)
self.register_buffer("sin_cached", torch.sin(freqs), persistent=False)
x_even = x[..., ::2] # 0,2,4,...
x_odd = x[..., 1::2] # 1,3,5,...
# 从缓存中选取相应长度的 cos 和 sin 值
cos = self.cos_cached[token_positions] # (..., seq_len, d_k//2)
sin = self.sin_cached[token_positions] # (..., seq_len, d_k//2)
even = cos * x_even - sin * x_odd
odd = sin * x_even + cos * x_odd
return torch.stack([even, odd], dim=-1).flatten(-2) # (..., seq_len, d_k)
Scaled Dot-Product Attention
实现数值稳定的softmax:
def my_softmax(in_features: Float[Tensor, " ..."], dim: int) -> Float[Tensor, " ..."]:
# 首先对输入张量的指定维度进行最大值归一化
max_vals = torch.max(in_features, dim=dim, keepdim=True).values # [batch_size, seq_len, ..., 1]
x = in_features - max_vals # 归一化
# 对归一化后的值应用 exp
exp_x = torch.exp(x)
# 对指定维度上所有的 exp(x) 进行求和
sum_exp_x = torch.sum(exp_x, dim=dim, keepdim=True)
# 返回 softmax 结果
return exp_x / sum_exp_x定义注意力操作计算:
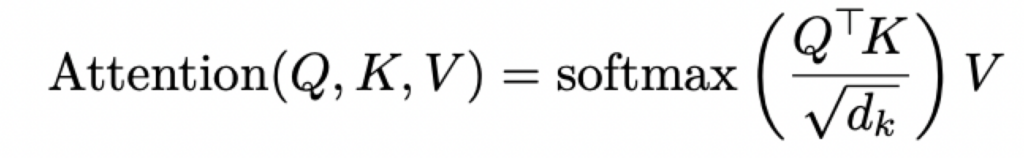
Mask矩阵M是一个nxm的矩阵,其中n是query的数量,m是key的数量,矩阵中的元素为布尔值。当(i, j)为True时,表示query i会attend到key j。
计算上,比直接对子序列逐一计算 attention 更高效,做法是对 softmax 之前的打分矩阵在 mask 为 False 的位置加上 −∞。
在自注意力(self-attention)做自回归(autoregressive)语言模型时,通常使用“下三角”掩码,保证当前位置只能 attend 自己及之前的位置(不能看到未来)。
实现点积注意力:
def run_scaled_dot_product_attention(
Q: Float[Tensor, " ... queries d_k"],
K: Float[Tensor, " ... keys d_k"],
V: Float[Tensor, " ... values d_v"],
mask: Float[Tensor, " ... queries keys"] | None = None,
) -> Float[Tensor, " ... queries d_v"]:
"""
Given key (K), query (Q), and value (V) tensors, return
the output of your scaled dot product attention implementation.
Args:
Q (Float[Tensor, " ... queries d_k"]): Query tensor
K (Float[Tensor, " ... keys d_k"]): Key tensor
V (Float[Tensor, " ... values d_v"]): Values tensor
mask (Float[Tensor, " ... queries keys"] | None): Mask tensor
Returns:
Float[Tensor, " ... queries d_v"]: Output of SDPA
"""
#raise NotImplementedError
# values == keys
d_k = Q.shape[-1]
attn_logits = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5) # (..., n_queries, n_keys)
if mask is not None:
attn_logits = attn_logits.masked_fill(mask == 0, float('-inf'))
# 沿着keys的维度进行
attn_weights = my_softmax(attn_logits, dim=-1) # (..., n_queries, n_keys)
return torch.matmul(attn_weights, V)Causal Multi-Head Self-Attention
相关公式:
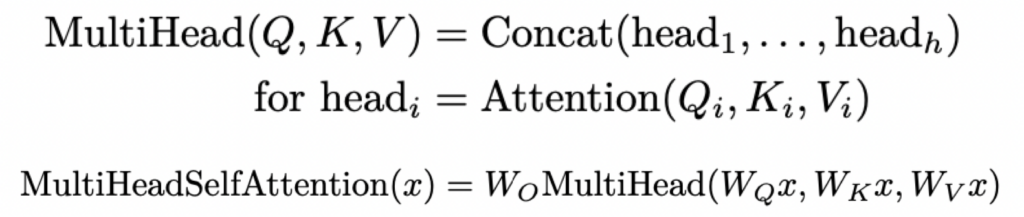
代码实现:
class MultiheadSelfAttention(nn.Module):
def __init__(self, d_model, num_heads, theta=10000.0, max_seq_len=512, apply_rope=False, device=None):
super(MultiheadSelfAttention, self).__init__()
self.d_model = d_model
self.n_heads = num_heads
self.d_k = self.d_model // self.n_heads
self.d_v = self.d_k
self.device = device
self.apply_rope = apply_rope
self.rope = RotaryPositionalEmbedding(theta=theta, d_k=self.d_k, max_seq_len=max_seq_len, device=self.device)
self.wq = Linear(in_features=self.d_model, out_features=self.d_model)
self.wk = Linear(in_features=self.d_model, out_features=self.d_model)
self.wv = Linear(in_features=self.d_model, out_features=self.d_model)
self.wo = Linear(in_features=self.d_model, out_features=self.d_model)
def forward(self, x: torch.Tensor):
batch_size, seq_len, _ = x.shape
Q = self.wq(x) # (B, L, d_k * n_heads)
K = self.wk(x) # (B, L, d_k * n_heads)
V = self.wv(x) # (B, L, d_v * n_heads)
# 变为多头: (B, n_heads, L, d_k)
Q = Q.view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, seq_len, self.n_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len, self.n_heads, self.d_v).transpose(1, 2)
# (B, L)
token_positions = torch.arange(seq_len, device=x.device).unsqueeze(0).expand(batch_size, seq_len)
# apply RoPE
if self.apply_rope:
# (B*H, L, d_k)
Q_rope = self.rope(Q.flatten(0,1), token_positions.repeat(self.n_heads, 1))
K_rope = self.rope(K.flatten(0,1), token_positions.repeat(self.n_heads, 1))
# 恢复维度
Q = Q_rope.view(batch_size, self.n_heads, seq_len, self.d_k)
K = K_rope.view(batch_size, self.n_heads, seq_len, self.d_k)
# 创建下三角矩阵 (1表示可见, 0表示不可见)
mask = torch.tril(torch.ones(seq_len, seq_len, dtype=torch.float32, device=self.device))
mask = mask.unsqueeze(0).unsqueeze(0) # [1, 1, seq_len, seq_len]
mask = mask.expand(batch_size, self.n_heads, seq_len, seq_len)
# 计算注意力分数
attn = run_scaled_dot_product_attention(Q, K, V, mask) # (B, H, L, d_v)
# 拼接所有 head
attn = attn.transpose(1, 2).contiguous().view(batch_size, seq_len, self.n_heads * self.d_v)
# 输出
#return torch.matmul(attn, o_proj_weight.transpose(-2, -1))
return self.wo(attn)The Full Transformer LM
每个Transformer block包括multihead self attention和feed-forward network子层,在每个子层先RMSNorm,然后主操作(MHA/FF),最后加上残差连接。
具体来说,multihead self attention子层公式如下:
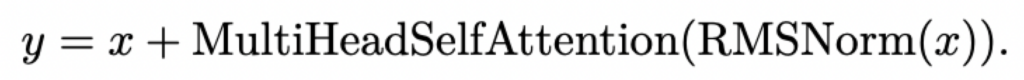
然后feed-forward network子层使用前面的SwiGLU:
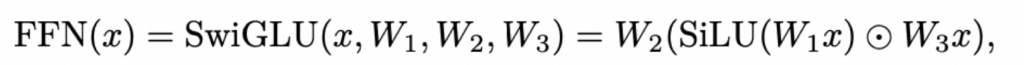
Transformer block代码实现:
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, d_ff, max_seq_len, theta, device=None):
super(TransformerBlock, self).__init__()
self.rmsnorm1 = RMSNorm(d_model=d_model, device=device)
self.mha = MultiheadSelfAttention(d_model=d_model, num_heads=num_heads, theta=theta, max_seq_len=max_seq_len, apply_rope=True, device=device)
self.rmsnorm2 = RMSNorm(d_model=d_model, device=device)
self.ffn = SwiGLU(d_model=d_model, d_ff=d_ff, device=device)
def forward(self, x):
# MHA
x1 = self.rmsnorm1(x)
x2 = x + self.mha(x1)
# FFN
x3 = self.rmsnorm2(x2)
return x2 + self.ffn(x3)完整的Transformer LM(到最终softmax之前)代码实现:
def run_transformer_lm(
vocab_size: int,
context_length: int,
d_model: int,
num_layers: int,
num_heads: int,
d_ff: int,
rope_theta: float,
weights: dict[str, Tensor],
in_indices: Int[Tensor, " batch_size sequence_length"],
) -> Float[Tensor, " batch_size sequence_length vocab_size"]:
"""Given the weights of a Transformer language model and input indices,
return the output of running a forward pass on the input indices.
This function should use RoPE.
Args:
vocab_size (int): The number of unique items in the output vocabulary to be predicted.
context_length (int): The maximum number of tokens to process at once.
d_model (int): The dimensionality of the model embeddings and sublayer outputs.
num_layers (int): The number of Transformer layers to use.
num_heads (int): Number of heads to use in multi-headed attention. `d_model` must be
evenly divisible by `num_heads`.
d_ff (int): Dimensionality of the feed-forward inner layer (section 3.3).
rope_theta (float): The RoPE $\Theta$ parameter.
weights (dict[str, Tensor]):
State dict of our reference implementation. {num_layers} refers to an
integer between `0` and `num_layers - 1` (the layer index).
The keys of this dictionary are:
- `token_embeddings.weight`
Token embedding matrix. Shape is (vocab_size, d_model).
- `layers.{num_layers}.attn.q_proj.weight`
The query projections for all `num_heads` attention heads.
Shape is (num_heads * (d_model / num_heads), d_model).
The rows are ordered by matrices of shape (num_heads, d_k),
so `attn.q_proj.weight == torch.cat([q_heads.0.weight, ..., q_heads.N.weight], dim=0)`.
- `layers.{num_layers}.attn.k_proj.weight`
The key projections for all `num_heads` attention heads.
Shape is (num_heads * (d_model / num_heads), d_model).
The rows are ordered by matrices of shape (num_heads, d_k),
so `attn.k_proj.weight == torch.cat([k_heads.0.weight, ..., k_heads.N.weight], dim=0)`.
- `layers.{num_layers}.attn.v_proj.weight`
The value projections for all `num_heads` attention heads.
Shape is (num_heads * (d_model / num_heads), d_model).
The rows are ordered by matrices of shape (num_heads, d_v),
so `attn.v_proj.weight == torch.cat([v_heads.0.weight, ..., v_heads.N.weight], dim=0)`.
- `layers.{num_layers}.attn.output_proj.weight`
Weight of the multi-head self-attention output projection
Shape is ((d_model / num_heads) * num_heads, d_model).
- `layers.{num_layers}.ln1.weight`
Weights of affine transform for the first RMSNorm
applied in the transformer block.
Shape is (d_model,).
- `layers.{num_layers}.ffn.w1.weight`
Weight of the first linear transformation in the FFN.
Shape is (d_model, d_ff).
- `layers.{num_layers}.ffn.w2.weight`
Weight of the second linear transformation in the FFN.
Shape is (d_ff, d_model).
- `layers.{num_layers}.ffn.w3.weight`
Weight of the third linear transformation in the FFN.
Shape is (d_model, d_ff).
- `layers.{num_layers}.ln2.weight`
Weights of affine transform for the second RMSNorm
applied in the transformer block.
Shape is (d_model,).
- `ln_final.weight`
Weights of affine transform for RMSNorm applied to the output of the final transformer block.
Shape is (d_model, ).
- `lm_head.weight`
Weights of the language model output embedding.
Shape is (vocab_size, d_model).
in_indices (Int[Tensor, "batch_size sequence_length"]) Tensor with input indices to run the language model on. Shape is (batch_size, sequence_length), where
`sequence_length` is at most `context_length`.
Returns:
Float[Tensor, "batch_size sequence_length vocab_size"]: Tensor with the predicted unnormalized
next-word distribution for each token.
"""
#raise NotImplementedError
# Embedding
embedding = Embedding(vocab_size, d_model)
embedding_state_dict = {"embedding_matrix": weights["token_embeddings.weight"]}
embedding.load_state_dict(embedding_state_dict)
x = embedding(in_indices)
# Transformer Blocks
for i in range(num_layers):
transformer_block = TransformerBlock(d_model=d_model, num_heads=num_heads, d_ff=d_ff, max_seq_len=context_length, theta=rope_theta)
transformer_block_state_dict = {
"rmsnorm1.gamma": weights["layers.{}.ln1.weight".format(i)],
"mha.wq.weight": weights["layers.{}.attn.q_proj.weight".format(i)],
"mha.wk.weight": weights["layers.{}.attn.k_proj.weight".format(i)],
"mha.wv.weight": weights["layers.{}.attn.v_proj.weight".format(i)],
"mha.wo.weight": weights["layers.{}.attn.output_proj.weight".format(i)],
"rmsnorm2.gamma": weights["layers.{}.ln2.weight".format(i)],
"ffn.w1.weight": weights["layers.{}.ffn.w1.weight".format(i)],
"ffn.w2.weight": weights["layers.{}.ffn.w2.weight".format(i)],
"ffn.w3.weight": weights["layers.{}.ffn.w3.weight".format(i)],
}
transformer_block.load_state_dict(transformer_block_state_dict)
x = transformer_block(x)
# final RMSNorm
final_rmsnorm = RMSNorm(d_model=d_model)
final_rmsnorn_state_dict = {"gamma": weights["ln_final.weight"]}
final_rmsnorm.load_state_dict(final_rmsnorn_state_dict)
x = final_rmsnorm(x)
# output embedding
output_embedding = Linear(in_features=d_model, out_features=vocab_size)
output_embedding_state_dict = {"weight": weights["lm_head.weight"]}
output_embedding.load_state_dict(output_embedding_state_dict)
x = output_embedding(x)
return xResource accounting
步骤:
- Write down all the matrix multiplies in a Transformer forward pass;
- Convert each matrix multiply into FLOPs required.
其中第2步的计算规则:
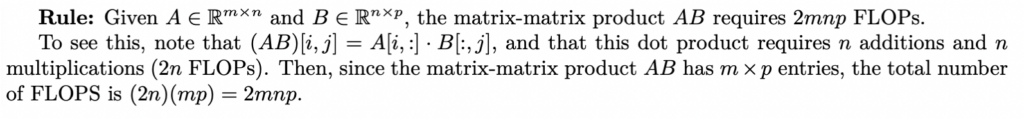
一个例子:
考虑GPT-2 XL,配置如下:
vocab_size : 50247
context_length : 1024
num_layers : 48
d_model : 1600
num_heads : 25
d_ff : 6400
模型中可训练参数如下:
(1)Embedding层:
权重矩阵: (d_model, vocab_size)
(2)每个Transformer Block x num_layers:
第一个RMSNorm参数gamma:(d_model,)
Q投影权重矩阵:(d_model, d_model)
K投影权重矩阵:(d_model, d_model)
V投影权重矩阵:(d_model, d_model)
Output投影矩阵:(d_model, d_model)
第二个RMSNorm参数gamma:(d_model,)
前馈层w1权重矩阵:(d_model, d_ff)
前馈层w2权重矩阵:(d_ff, d_model)
前馈层w3权重矩阵:(d_model, d_ff) 【了解到GPT-2 XL没有w3故不参与计算】
(3)Final RMSNorm层:
参数gamma:(d_model,)
(4)Output线性层【与Embedding层共享权重】:
权重矩阵:(vocab_size, d_model)
【以下计算时只考虑矩阵中参数】
模型总参数数量:
50247 * 1600 + 48 * (1600 * 1600 * 4 + 1600 * 6400 * 2) = 1554955200 (约1.5B)
如果参数用单精度浮点数存储,则加载该模型所需要的内存为 :
1.5B * 4 Bytes = 6B Bytes (约5.59GB)
前向传播过程中的矩阵乘法:
MHA:
Q、K、V投影矩阵与输入相乘:2 * d_model * d_model * context_length * 3
Q、K相乘再乘V计算注意力分数: 2 * d_model * context_length * context_length * 2
注意力分数和Output投影矩阵相乘:2 * d_model * d_model * context_length
FFN:
w1、w2矩阵与输入相乘:2 * d_model * d_ff * context_length * 2
所以总的FLOPs为:(2 * 1600 * 1600 * 1024 * 3 + 2 * 1600 * 1024 * 1024 * 2 + 2 * 1600 * 1600 * 1024 + 2 * 1600 * 6400 * 1024 * 2) * 48 = 3342021427200 (约3.342 × 10^12)
可以看到前馈层FLOPs占比比注意力层更高。
Training a Transformer LM
Loss:需要定义损失函数(cross-entropy);
Optimizer:需要定义优化器来最小化loss(AdamW);
Training loop:加载数据、保存检查点、管理训练等。
Cross-entropy loss
定义:
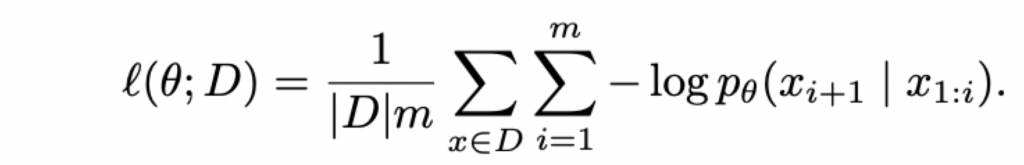
注意到,Transformer的一次前向传播就可以生成所有i = 1,…,m的 p_theta(x(i+1) | x(1:i)):
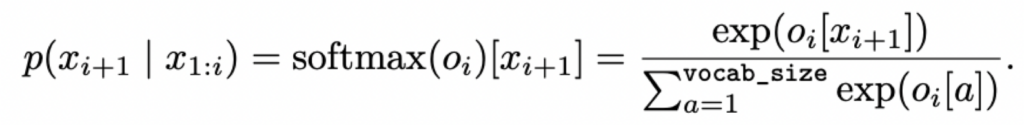
Cancel out log and exp技巧:
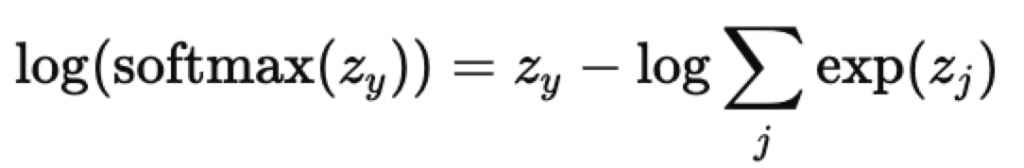
代码实现:
def run_cross_entropy(
inputs: Float[Tensor, " batch_size vocab_size"], targets: Int[Tensor, " batch_size"]
) -> Float[Tensor, ""]:
"""Given a tensor of inputs and targets, compute the average cross-entropy
loss across examples.
Args:
inputs (Float[Tensor, "batch_size vocab_size"]): inputs[i][j] is the
unnormalized logit of jth class for the ith example.
targets (Int[Tensor, "batch_size"]): Tensor of shape (batch_size,) with the index of the correct class.
Each value must be between 0 and `num_classes - 1`.
Returns:
Float[Tensor, ""]: The average cross-entropy loss across examples.
"""
#raise NotImplementedError
vocab_dim = inputs.shape[-1]
# handle batch-like dim
inputs_flat = inputs.reshape(-1, vocab_dim)
targets_flat = targets.reshape(-1)
# 最大值归一化
shifted_logits = inputs_flat - inputs_flat.max(dim=-1, keepdim=True).values
# Cancel out log and exp
logsumexp = torch.log(torch.exp(shifted_logits).sum(dim=-1))
# 得到每个样本正确标签的logit(即公式中的z_y)
correct_logit = shifted_logits.gather(dim=-1, index=targets_flat.unsqueeze(-1)).squeeze(-1)
# -logp
loss_per_sample = -(correct_logit - logsumexp)
# average cross-entropy loss
return loss_per_sample.mean()Perplexity:评估模型时会用到,计算公式如下:
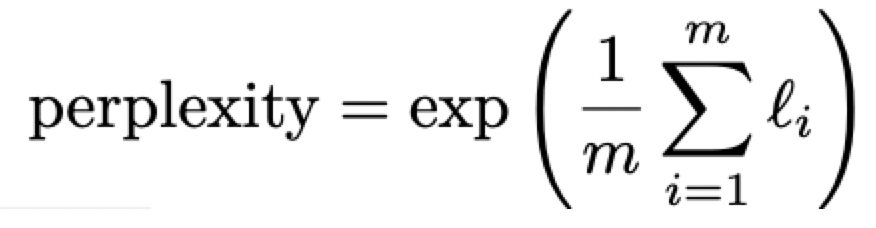
其中,l_1,…,l_m是长度为m的序列计算出的cross-entropy loss。
The SGD Optimizer
for each step t = 0, …, T – 1:
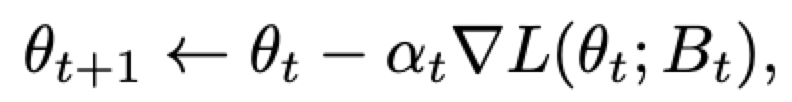
其中,B_t是从数据集D中随机取出的批量,学习率和批量大小是超参数。
逐渐减小学习率的SGD示例:
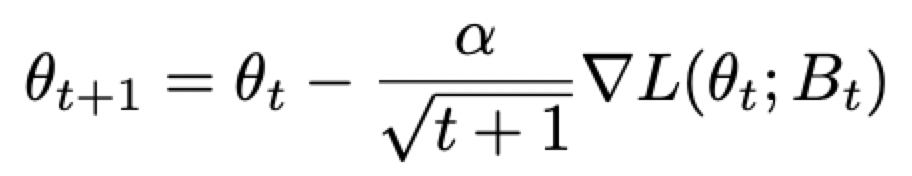
AdamW
AdamW 是有状态的:对于每个参数,它都会跟踪其一阶矩和二阶矩的运行估计值。因此,AdamW 使用额外的内存来换取更高的稳定性和收敛性。除了学习率 α 之外,AdamW 还包含一对超参数 (β1, β2),用于控制矩估计值的更新,以及权重衰减率 λ。典型的应用会将 (β1, β2) 设置为 (0.9, 0.999),但像 LLaMA和 GPT-3 这样的大型语言模型通常使用 (0.9, 0.95) 进行训练。该算法可以写成如下形式,其中 ε 是一个很小的值(例如 10⁻⁸),用于在 v 取极小值时提高数值稳定性,算法如下:

代码实现:
class AdamW(torch.optim.Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=1e-2):
if lr < 0:
raise ValueError(f"Invalid learning rate: {lr}")
defaults = {
"lr": lr,
"betas": betas,
"eps": eps,
"weight_decay": weight_decay
}
super().__init__(params, defaults)
def step(self, closure: Optional[Callable] = None):
loss = None if closure is None else closure()
for group in self.param_groups:
lr = group["lr"]
beta1 = group["betas"][0]
beta2 = group["betas"][1]
eps = group["eps"]
weight_decay = group["weight_decay"]
for p in group["params"]:
if p.grad is None:
continue
state = self.state[p]
t = state.get("t", 1)
m = state.get("m", 0)
v = state.get("v", 0)
grad = p.grad.data
m = beta1 * m + (1 - beta1) * grad
v = beta2 * v + (1 - beta2) * (grad ** 2)
lr_t = lr * (math.sqrt(1 - beta2 ** t) / (1 - beta1 ** t))
p.data -= lr_t * m / (torch.sqrt(v) + eps)
p.data = p.data - lr * weight_decay * p.data
state["t"] = t + 1
state["m"] = m
state["v"] = v
return lossResource accountinging for training with AdamW
计算AdamW在训练期间(前向 + 反向 + 优化器更新)的峰值内存,涉及的参数如下:
batch_size、vocab_size、context_length、num_layers、d_model、num_heads、d_ff=4 * d_model、d_k = d_model / num_heads,使用float32存储。
(1)参数(Parameters)部分
embedding(与lm_head共享权重):vocab_size * d_model
每个Transformer block:
Attention投影矩阵(Q、K、V、Output):4 * d_model * d_model
FFN矩阵(w1和w2):2 * d_ff * d_model = 8 * d_model * d_model
两个RMSNorm参数gamma:2 * d_model
合计:12 * d_model * d_model + 2 * d_model
Final RMSNorm参数gamma:d_model
参数总计P:vocab_size * d_model + num_layers * (12 * d_model * d_model + 2 * d_model) + d_model
占用的字节数:4 * P
(2)激活值(Activations)部分
embedding结果:batch_size * context_length * d_model
每个Transformer block:
MHA部分:
两个RMSNorm结果:2 * batch_size * context_length * d_model
Q、K、V投影矩阵结果:3 * batch_size * context_length * d_model
Attention分数(QK^T)和attn_probs(softmax结果):2 * batch_size * num_heads * context_length^2
attn_probs和V结果:batch_size * context_length * d_model
Output投影矩阵结果:batch_size * context_length * d_model
FFN部分:
w1结果:batch_size * context_length * d_ff = batch_size * context_length * 4 * d_model
SiLU激活:batch_size * context_length * d_ff = batch_size * context_length * 4 * d_model
w2结果:batch_size * context_length * d_model
Final RMSNorm结果:batch_size * context_length * d_model
Output logits:batch_size * context_length * vocab_size
(3)梯度(Gradients)部分
与参数部分相同。
(4)优化器状态(AdamW的m和v)
参数部分的2倍。
【与模型的前向和反向传播相比,优化器的FLOPs在资源核算时可以忽略(只考虑其存储资源需求即可)。】
Learning rate scheduling
在训练 Transformer 模型时,通常会使用学习率递减策略,即初始学习率较高,在训练初期进行快速更新,然后随着模型的训练逐渐减小学习率。
学习率递减策略是一个函数,它接受当前步骤 t 和其他相关参数(例如初始学习率和最终学习率),并返回在步骤 t 进行梯度更新时使用的学习率。最简单的策略是使用常数函数,它对于任何 t 值都返回相同的学习率。
实现用于训练 LLaMA 模型的余弦退火策略(cosine annealing schedule),余弦退火学习率调度方案考虑以下因素:(i) 当前迭代次数 t,(ii) 最大学习率 αmax,(iii) 最小(最终)学习率 αmin,(iv) 预热迭代次数 Tw,以及 (v) 余弦退火迭代次数 Tc。第 t 次迭代的学习率定义为:
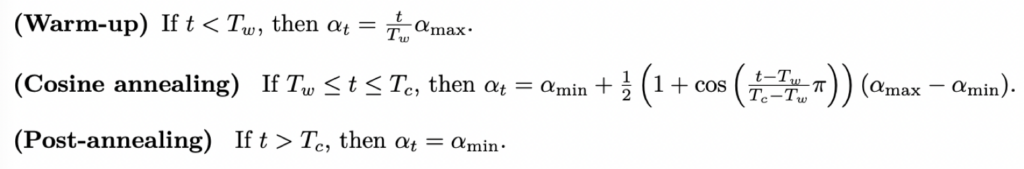
代码实现:
def run_get_lr_cosine_schedule(
it: int,
max_learning_rate: float,
min_learning_rate: float,
warmup_iters: int,
cosine_cycle_iters: int,
):
"""
Given the parameters of a cosine learning rate decay schedule (with linear
warmup) and an iteration number, return the learning rate at the given
iteration under the specified schedule.
Args:
it (int): Iteration number to get learning rate for.
max_learning_rate (float): alpha_max, the maximum learning rate for
cosine learning rate schedule (with warmup).
min_learning_rate (float): alpha_min, the minimum / final learning rate for
the cosine learning rate schedule (with warmup).
warmup_iters (int): T_w, the number of iterations to linearly warm-up
the learning rate.
cosine_cycle_iters (int): T_c, the number of cosine annealing iterations.
Returns:
Learning rate at the given iteration under the specified schedule.
"""
#raise NotImplementedError
if it < warmup_iters:
return (it / warmup_iters) * max_learning_rate
elif it >= warmup_iters and it <= cosine_cycle_iters:
return min_learning_rate + 0.5 * (1 + math.cos(((it - warmup_iters) / (cosine_cycle_iters - warmup_iters)) * math.pi)) * (max_learning_rate - min_learning_rate)
elif it > cosine_cycle_iters:
return min_learning_rateGradient clipping
在训练过程中,我们有时会遇到梯度过大的训练样本,这会导致训练不稳定。为了缓解这个问题,实践中常用的一种技术是梯度裁剪。其基本思想是在每次反向传播之后、进行优化器迭代之前,对梯度的范数进行限制。
代码实现:
def run_gradient_clipping(parameters: Iterable[torch.nn.Parameter], max_l2_norm: float) -> None:
"""Given a set of parameters, clip their combined gradients to have l2 norm at most max_l2_norm.
Args:
parameters (Iterable[torch.nn.Parameter]): collection of trainable parameters.
max_l2_norm (float): a positive value containing the maximum l2-norm.
The gradients of the parameters (parameter.grad) should be modified in-place.
"""
#raise NotImplementedError
g2sum = 0.0
for p in parameters:
if p.grad is None:
continue
g2sum += torch.sum(p.grad.data ** 2)
g_l2 = torch.sqrt(g2sum)
if g_l2 > max_l2_norm:
clip_rate = max_l2_norm / (g_l2 + 1e-6)
for p in parameters:
if p.grad is None:
continue
p.grad.data *= clip_rate
returnData Loader
分词后的数据是一个token序列,即使源数据可能包含多个文档(例如,不同的网页或源代码文件),通常的做法是将所有这些文档连接成一个token序列,并在它们之间添加分隔符(例如 <|endoftext|> 标记)。
data loader把这些token序列转换为批次流,其中每个批次包含 B 个长度为 m 的序列,以及左移1个token的序列。例如,对于 B = 1,m = 3,([x2, x3, x4], [x3, x4, x5]) 就是一个可能的批次。
代码实现:
def run_get_batch(
dataset: npt.NDArray, batch_size: int, context_length: int, device: str, idx: Optional[int] = None
) -> tuple[torch.Tensor, torch.Tensor]:
"""
Given a dataset (a 1D numpy array of integers) and a desired batch size and
context length, sample language modeling input sequences and their corresponding
labels from the dataset.
Args:
dataset (np.array): 1D numpy array of integer token IDs in the dataset.
batch_size (int): Desired batch size to sample.
context_length (int): Desired context length of each sampled example.
device (str): PyTorch device string (e.g., 'cpu' or 'cuda:0') indicating the device
to place the sampled input sequences and labels on.
Returns:
Tuple of torch.LongTensors of shape (batch_size, context_length). The first tuple item
is the sampled input sequences, and the second tuple item is the corresponding
language modeling labels.
"""
#raise NotImplementedError
n_samples = len(dataset)
max_start = n_samples - context_length - 1
if idx is not None:
start_indices = np.arange(idx, idx + batch_size) # shape: (batch_size,)
else:
# 一次性随机选择所有起始位置
start_indices = np.random.randint(0, max_start + 1, size=batch_size)
# 向量化创建所有序列
# 使用广播生成所有索引矩阵
# start_indices[:, None] 形状 (batch_size, 1)
# np.arange(context_length + 1) 形状 (context_length + 1,)
# 相加得到 (batch_size, context_length + 1) 的索引矩阵
indices = start_indices[:, None] + np.arange(context_length + 1)
# 一次性取出所有数据
sequences_array = dataset[indices] # (batch_size, context_length + 1)
# 分割输入和目标
inputs = torch.from_numpy(sequences_array[:, :-1]).to(device) # 除最后一个token
targets = torch.from_numpy(sequences_array[:, 1:]).to(device) # 除第一个token
return inputs, targetsCheckpointing
在训练过程中保存模型权重、优化器状态、训练轮次等信息。
代码实现:
def save_checkpoint(model, optimizer, iteration, out):
obj = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'iteration': iteration
}
torch.save(obj, out)
return
def load_checkpoint(src, model, optimizer):
obj = torch.load(src)
model.load_state_dict(obj['model'])
optimizer.load_state_dict(obj['optimizer'])
return obj['iteration']Training loop
from __future__ import annotations
import os
from typing import IO, Any, BinaryIO, Optional
from collections.abc import Iterable, Callable
from jaxtyping import Float, Int
import numpy.typing as npt
import torch
from torch import Tensor
import torch.nn as nn
import torch.nn.functional as F
import math
import numpy as np
from adapters import * # type: ignore
import argparse
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import os
import time
try:
import wandb
WANDB_AVAILABLE = True
except ImportError:
WANDB_AVAILABLE = False
class MemmapDataset(Dataset):
"""
A dataset that does zero-copy loading via np.memmap.
"""
def __init__(self, data_path):
"""
data_path: memmap file
"""
self.data = np.memmap(data_path, dtype="int64", mode="r")
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
class SimpleTransformer(nn.Module):
def __init__(
self,
vocab_size,
context_length,
d_model,
num_layers,
num_heads,
d_ff,
rope_theta=10000.0,
device=None,
dtype=None,
):
super(SimpleTransformer, self).__init__()
self.vocab_size = vocab_size
self.context_length = context_length
self.d_model = d_model
self.num_layers = num_layers
self.num_heads = num_heads
self.d_ff = d_ff
self.rope_theta = rope_theta
self.device = device
self.dtype = dtype
# Token Embedding
self.tok_embedding = Embedding( # type: ignore
num_embeddings=vocab_size,
embedding_dim=d_model,
device=device,
dtype=dtype,
)
# Transformer Blocks
self.blocks = nn.ModuleList([
TransformerBlock( # type: ignore
d_model=d_model,
num_heads=num_heads,
d_ff=d_ff,
max_seq_len=context_length,
theta=rope_theta,
device=device,
)
for _ in range(num_layers)
])
# Final RMSNorm
self.final_norm = RMSNorm(d_model=d_model, device=device, dtype=dtype) # type: ignore
# LM Head (Linear)
self.lm_head = Linear( # type: ignore
in_features=d_model,
out_features=vocab_size,
device=device,
dtype=dtype,
)
def forward(self, token_ids: torch.Tensor):
"""
token_ids: (batch_size seq_len)
return: logits with (batch_size, seq_len, vocab_size)
"""
x = self.tok_embedding(token_ids) # (batch_size, seq_len, d_model)
for block in self.blocks:
x = block(x)
x = self.final_norm(x)
logits = self.lm_head(x) # (batch_size, seq_len, vocab_size)
return logits
def main(args):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 计算总步数信息
train_ds = MemmapDataset(args.train_data)
valid_ds = MemmapDataset(args.valid_data)
batches_per_epoch = len(train_ds) // args.batch_size
total_steps = batches_per_epoch * args.epochs
if args.max_steps > 0:
total_steps = min(total_steps, args.max_steps)
eval_steps = args.eval_every # 每多少步评估一次
save_steps = args.save_every # 每多少步保存一次
print(f"Training config: total_steps={total_steps}, eval_every={eval_steps}, save_every={save_steps}")
if args.use_wandb:
if not WANDB_AVAILABLE:
raise ImportError("You passed --use_wandb but wandb is not installed.")
wandb.init(project=args.wandb_project, config=vars(args))
train_ds = MemmapDataset(args.train_data)
valid_ds = MemmapDataset(args.valid_data)
print(f"Data loaded")
model = SimpleTransformer(
vocab_size=args.vocab_size,
context_length=args.context_length,
d_model=args.d_model,
num_layers=args.num_layers,
num_heads=args.num_heads,
d_ff=args.d_ff,
rope_theta=args.rope_theta,
device=device
)
model = model.to(device)
optimizer = AdamW(model.parameters(), lr=args.lr) # type: ignore
# 恢复训练状态
start_step = 0
start_epoch = 1
current_step = 0
best_valid_loss = float("inf")
if args.load_checkpoint and os.path.exists(args.load_checkpoint):
#iter_num = load_checkpoint(args.load_checkpoint, model, optimizer) # type: ignore
#print(f"Loaded checkpoint from {args.load_checkpoint}, iter: {iter_num}")
checkpoint = torch.load(args.load_checkpoint, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_step = checkpoint.get('step', 0)
start_epoch = checkpoint.get('epoch', 1)
best_valid_loss = checkpoint.get('best_valid_loss', float("inf"))
print(f"Loaded checkpoint from {args.load_checkpoint}, step: {start_step}, epoch: {start_epoch}")
# 记录实验日志文件
log_file = args.log_file if args.log_file else "experiment_log.txt"
log_f = open(log_file, "w") if args.save_log else None
if log_f:
log_f.write("=" * 80 + "\n")
log_f.write("Experiment Log\n")
log_f.write("=" * 80 + "\n")
log_f.write(f"Command: {args}\n\n")
log_f.write("step,epoch,train_loss,valid_loss,time_per_step,wallclock_time\n")
model.train()
step_times = []
wallclock_start = time.time()
valid_batches_per_epoch = len(valid_ds) // args.batch_size - 1
valid_batches_per_epoch = min(valid_batches_per_epoch, args.eval_steps)
for epoch in range(start_epoch, args.epochs + 1):
for batch_idx in range(batches_per_epoch):
step_start = time.time()
current_step += 1
print(f"[Step {current_step}/{total_steps}] (Epoch {epoch})")
# 准备数据
inputs, targets = run_get_batch(train_ds, args.batch_size, args.context_length, device) # type: ignore
# 前向传播
optimizer.zero_grad()
pred = model(inputs)
loss = run_cross_entropy(pred, targets) # type: ignore
loss.backward()
# 梯度裁剪(可选)
if args.grad_clip > 0:
run_gradient_clipping(model.parameters(), args.grad_clip)
optimizer.step()
# 记录步长时间
step_time = time.time() - step_start
step_times.append(step_time)
# 记录训练损失(每步都记录)
train_loss = loss.item()
# 定期评估验证损失
if current_step % eval_steps == 0:
model.eval()
total_valid_loss = 0
valid_batches = 0
with torch.no_grad():
for batch_idx in range(valid_batches_per_epoch):
val_inputs, val_targets = run_get_batch(valid_ds, args.batch_size, args.context_length, device, batch_idx) # type: ignore
val_pred = model(val_inputs)
val_loss = run_cross_entropy(val_pred, val_targets) # type: ignore
total_valid_loss += val_loss.item()
valid_batches += 1
valid_loss = total_valid_loss / valid_batches if valid_batches > 0 else float("inf")
model.train()
# 计算平均步长时间
avg_step_time = np.mean(step_times[-100:]) if step_times else step_time
wallclock_time = time.time() - wallclock_start
# 打印日志
print(f"[Step {current_step}/{total_steps}] (Epoch {epoch}) train={train_loss:.4f} valid={valid_loss:.4f} step_time={step_time:.3f}s avg_step={avg_step_time:.3f}s wallclock={wallclock_time:.1f}s")
# WandB 记录
if args.use_wandb:
wandb.log({
"train_loss": train_loss,
"valid_loss": valid_loss,
"step": current_step,
"epoch": epoch,
"step_time": step_time,
"avg_step_time": avg_step_time,
"wallclock_time": wallclock_time
})
# 记录到日志文件
if log_f:
log_f.write(f"{current_step},{epoch},{train_loss:.6f},{valid_loss:.6f},{avg_step_time:.6f},{wallclock_time:.6f}\n")
log_f.flush()
# 保存最佳模型
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
checkpoint = {
'step': current_step,
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_valid_loss': best_valid_loss,
}
torch.save(checkpoint, args.checkpoint_path)
print(f" -> Best model saved (valid_loss={valid_loss:.4f})")
# 定期保存检查点
if current_step % save_steps == 0:
checkpoint = {
'step': current_step,
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'best_valid_loss': best_valid_loss,
}
save_path = f"{args.checkpoint_path}.step{current_step}"
torch.save(checkpoint, save_path)
print(f" -> Checkpoint saved to {save_path}")
# 提前停止
if args.max_steps > 0 and current_step >= args.max_steps:
break
# 每个 epoch 结束后打印总结
avg_step_time_epoch = np.mean(step_times[-batches_per_epoch:]) if step_times else 0
print(f"[Epoch {epoch} completed] avg_step_time={avg_step_time_epoch:.3f}s, total_time={time.time() - wallclock_start:.1f}s")
if args.max_steps > 0 and current_step >= args.max_steps:
break
# 关闭日志文件
if log_f:
log_f.write("\n" + "=" * 80 + "\n")
log_f.write("Training completed\n")
log_f.write(f"Total steps: {current_step}\n")
log_f.write(f"Total wallclock time: {time.time() - wallclock_start:.1f}s\n")
log_f.write("=" * 80 + "\n")
log_f.close()
print("Training finished.")
print(f"Total steps: {current_step}, Best valid loss: {best_valid_loss:.4f}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Data
parser.add_argument("--train_data", type=str, required=True)
parser.add_argument("--valid_data", type=str, required=True)
# Model hyperparameters
parser.add_argument("--vocab_size", type=int, default=10000)
parser.add_argument("--context_length", type=int, default=256)
parser.add_argument("--d_model", type=int, default=512)
parser.add_argument("--num_layers", type=int, default=4)
parser.add_argument("--num_heads", type=int, default=16)
parser.add_argument("--d_ff", type=int, default=1344)
parser.add_argument("--rope_theta", type=float, default=10000.0)
# Optimizer hyperparameters
parser.add_argument("--lr", type=float, default=1e-4)
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--epochs", type=int, default=5)
parser.add_argument("--grad_clip", type=float, default=1.0)
# Evaluation and logging
parser.add_argument("--eval_every", type=int, default=500, help="Evaluate validation loss every N steps")
parser.add_argument("--save_every", type=int, default=2000, help="Save checkpoint every N steps")
parser.add_argument("--max_steps", type=int, default=-1, help="Maximum number of steps (negative for no limit)")
parser.add_argument("--eval_steps", type=int, default=100, help="Maximum number of eval steps")
# Checkpoints
parser.add_argument("--checkpoint_path", type=str, default="model.pt")
parser.add_argument("--load_checkpoint", type=str, default=None)
# Logging
parser.add_argument("--use_wandb", action="store_true")
parser.add_argument("--wandb_project", type=str, default="training-example")
parser.add_argument("--save_log", action="store_true", help="Save experiment log to file")
parser.add_argument("--log_file", type=str, default="experiment_log.csv", help="Log file path")
args = parser.parse_args()
main(args)
Generating text
解码步骤输入x_1…t,返回x_t+1:
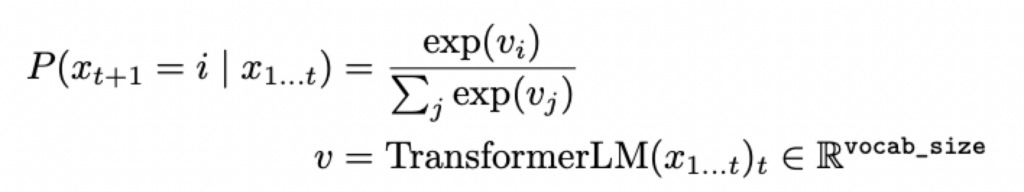
输出的每个batch的维度是(sequence_length, vocab_size),使用softmax得到概率分布。每步只取最后一个输出元素,然后把它加到之前的输入再继续生成下一个token,直到生成句尾token (<|endoftext|>) 或者达到指定的最大生成token数量。
解码tricks:
1.加入temperature scaling的softmax:
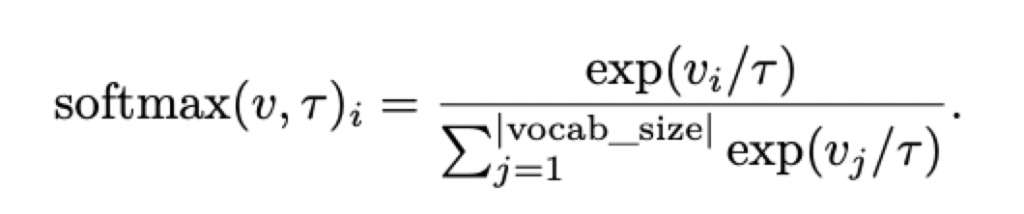
通过温度调整概率分布。
2.nucleus / top-p采样:
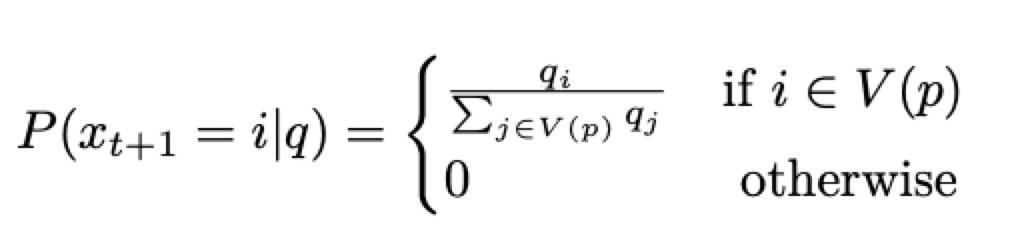
V(p)是概率之和大于p的token的最小集合,即只在该集合中采样。
代码实现如下:
def generate_with_top_p_and_temperature(
model,
tokenizer,
prompt,
device,
max_new_tokens=100,
temperature=1,
top_p=0.9
):
model.to(device)
model.eval()
input_ids = torch.tensor(tokenizer.encode(prompt)).unsqueeze(0).to(device)
generated_ids = []
with torch.no_grad():
for _ in range(max_new_tokens):
outputs = model(input_ids)
# 最后一个token的logits
next_token_logits = outputs[:, -1, :] # (batch_size, vocab_size)
if temperature > 0:
next_token_logits = next_token_logits / temperature
else:
# 温度=0 时,直接取 argmax(贪婪解码)
next_token = torch.argmax(next_token_logits, dim=-1, keepdim=True)
if next_token.item() == 0:
break
input_ids = torch.cat([input_ids, next_token], dim=-1)
generated_ids.append(next_token.item())
continue
probs = my_softmax(next_token_logits, dim=-1)
if top_p < 1.0:
# 按概率降序排序
sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)
# 找到累积概率超过 top_p 的位置
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
mask = cumulative_probs > top_p
# 至少保留一个 token
mask[:, 1:] = mask[:, :-1].clone()
mask[:, 0] = False
# 将超出 top_p 的 token 概率设为 0
sorted_probs[mask] = 0
# 重新归一化
sorted_probs = sorted_probs / sorted_probs.sum(dim=-1, keepdim=True)
# 从截断后的分布中采样
sampled_idx = torch.multinomial(sorted_probs, num_samples=1)
# 映射回原始 token ID
next_token = sorted_indices.gather(dim=-1, index=sampled_idx)
else:
# 直接采样
next_token = torch.multinomial(probs, num_samples=1)
if next_token.item() == 0:
break
input_ids = torch.cat([input_ids, next_token], dim=-1)
generated_ids.append(next_token.item())
generated_text = tokenizer.decode(generated_ids)
return generated_text
Experiments
数据集:TinyStories,模型参数量:17M,超参数:
vocab_size 10000
context_length 256
d_model 512
d_ff 1344
RoPE theta 10000.0
num_layers 4
num_heads 16
total tokens processed 327680000(计算资源上限,= batch_size * total_step * context_length)
实验:学习率搜索
1.学习率范围测试:在一个训练 run 中,让学习率从极小值(如 1e-7)指数增长到极大值(如 1e-1),画出 loss 随学习率变化的曲线;
2.对数网格扫描:[1e-5, 3e-5, 1e-4, 3e-4, 1e-3];
3.贝叶斯优化:使用 Optuna、Weights & Biases Sweeps 等工具,基于历史实验自动推荐下一组学习率。
本实验采用第2种方法,尝试了[1e-5, 1e-4, 1e-3, 5e-3]
(batch_size=64,total_step=20000,每500步进行验证,验证步数100.)
实验结果:
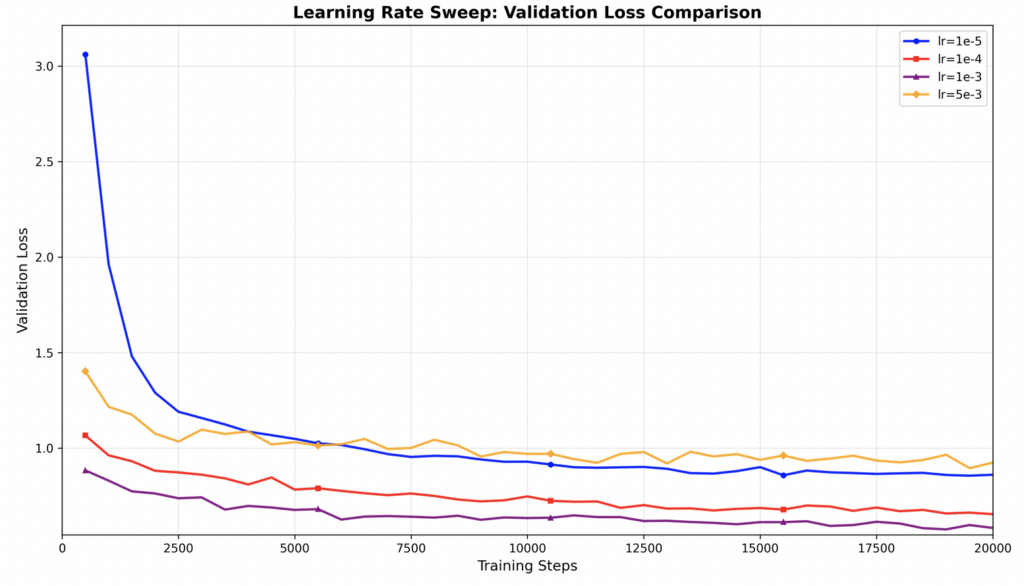
附一张模型训练后生成效果图:
发表回复